CS-443 Machine Learning
The course follows a few books:
- Christopher Bishop, Pattern Recognition and Machine Learning
- Kevin Patrick Murphy, Machine Learning: a Probabilistic Perspective
- Michael Nielsen, Neural Networks and Deep Learning
The repository for code labs and lecture notes is on GitHub. A useful website for this course is matrixcalculus.org.
- Linear regression
- Cost functions
- Optimization
- Least squares
- Maximum likelihood
- Overfitting and underfitting
- Regularization
- Model selection
- Classification
- Logistic regression
- Generalized Linear Models
- Nearest neighbor classifiers and the curse of dimensionality
- Support Vector Machines
- Unsupervised learning
- Matrix Factorization
- SVD and PCA
- Neural Networks
- Bayes Nets
In this course, we’ll always denote the dataset as a matrix , where is the data size and is the dimensionality, or the number of features. We’ll always use subscript for data point, and for feature. The labels, if any, are denoted in a vector, and the weights are denoted by :
Vectors are denoted in bold and lowercase (e.g. or ), and matrices are bold and uppercase (e.g. ). Scalars and functions are in normal font weight1.
Linear regression
A linear regression is a model that assumes a linear relationship between inputs and the output. We will study three types of methods:
- Grid search
- Iterative optimization algorithms
- Least squares
Simple linear regression
For a single input dimension (), we can use a simple linear regression, which is given by:
are the parameters of the model.
Multiple linear regression
If our data has multiple input dimensions, we obtain multivariate linear regression:
👉 If we wanted to be a little more strict, we should write , as the model of course also depends on the weights.
The tilde notation means that we have included the offset term , also known as the bias:
The problem
If the number of parameters exceeds the number of data examples, we say that the task is under-determined. This can be solved by regularization, which we’ll get to more precisely later.
Cost functions
is the data, which we can easily understand where comes from. But how does one find a good from the data?
A cost function (also called loss function) is used to learn parameters that explain the data well. It quantifies how well our model does by giving errors a score, quantifying penalties for errors. Our goal is to find parameters that minimize the loss functions.
Properties
Desirable properties of cost functions are:
- Symmetry around 0: that is, being off by a positive or negative amount is equivalent; what matters is the amplitude of the error, not the sign.
- Robustness: penalizes large errors at about the same rate as very large errors. This is a way to make sure that outliers don’t completely dominate our regression.
Good cost functions
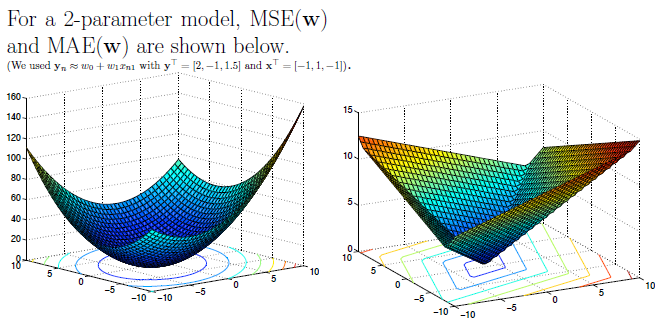
MSE
Probably the most commonly used cost function is Mean Square Error (MSE):
MSE is symmetrical around 0, but also tends to penalize outliers quite harshly (because it squares error): MSE is not robust. In practice, this is problematic, because outliers occur more often than we’d like to.
Note that we often use MSE with a factor instead of . This is because it makes for a cleaner derivative, but we’ll get into that later. Just know that for all intents and purposes, it doesn’t really change anything about the behavior of the models we’ll study.
MAE
When outliers are present, Mean Absolute Error (MAE) tends to fare better:
Instead of squaring, we take the absolute value. This is more robust. Note that MAE isn’t differentiable at 0, but we’ll talk about that later.
There are other cost functions that are even more robust; these are available as additional reading, but are not exam material.
Convexity
A function is convex iff a line joining two points never intersects with the function anywhere else. More strictly defined, a function with is convex if, for any , and for any , we have:
A function is strictly convex if the above inequality is strict (). This inequality is known as Jensen’s inequality.
A strictly convex function has a unique global minimum . For convex functions, every local minimum is a global minimum. This makes it a desirable property for loss functions, since it means that cost function optimization is guaranteed to find the global minimum.
Linear (and affine) functions are convex, and sums of convex functions are also convex. Therefore, MSE and MAE are convex.
We’ll see another way of characterizing convexity for differentiable functions later in the course.
Optimization
Learning / Estimation / Fitting
Given a cost function (or loss function) , we wish to find which minimizes the cost:
This is what we call learning: learning is simply an optimization problem, and as such, we’ll use an optimization algorithm to solve it – that is, find a good .
Grid search
This is one of the simplest optimization algorithms, although far from being the most efficient one. It can be described as “try all the values”, a kind of brute-force algorithm; you can think of it as nested for-loops over the individual weights.
For instance, if our weights are , then we can try, say 4 values for , 4 values for , for a total of 16 values of .
But obviously, complexity is exponential (where is the number of values to try), which is really bad, especially when we can have millions of parameters. Additionally, grid search has no guarantees that it’ll find an optimum; it’ll just find the best value we tried.
If grid search sounds bad for optimization, that’s because it is. In practice, it is not used for optimization of parameters, but it is used to tune hyperparameters.
Optimization landscapes
Local minimum
A vector is a local minimum of a function (we’re interested in the minimum of cost functions , which we denote with , as opposed to any other value , but this obviously holds for any function) if such that
In other words, the local minimum is better than all the neighbors in some non-zero radius.
Global minimum
The global minimum is defined by getting rid of the radius and comparing to all other values:
Strict minimum
A minimum is said to be strict if the corresponding equality is strict for , that is, there is only one minimum value.
Smooth (differentiable) optimization
Gradient
A gradient at a given point is the slope of the tangent to the function at that point. It points to the direction of largest increase of the function. By following the gradient (in the opposite direction, because we’re searching for a minimum and not a maximum), we can find the minimum.
Gradient is defined by:
This is a vector, i.e. . Each dimension of the vector indicates how fast the cost changes depending on the weight .
Gradient descent
Gradient descent is an iterative algorithm. We start from a candidate , and iterate.
As stated previously, we’re adding the negative gradient to find the minimum, hence the subtraction.
is known as the step-size, which is a small value (maybe 0.1). You don’t want to be too aggressive with it, or you might risk overshooting in your descent. In practice, the step-size that makes the learning as fast as possible is often found by trial and error 🤷🏼♂️.
As an example, we will take an analytical look at a gradient descent, in order to understand its behavior and components. We will do gradient descent on a 1-parameter model ( and ), in which we minimize the MSE, which is defined as follows:
Note that we’re dividing by 2 on top of the regular MSE; it has no impact on finding the minimum, but when we will compute the gradient below, it will conveniently cancel out the .
The gradient of is:
Where denotes the average of all values. And thus, our gradient descent is given by:
In this case, we’ve managed to find to this exact problem analytically from gradient descent. This sequence is guaranteed to converge to 2. This would set the cost function to 0, which is the minimum.
The choice of has an influence on the algorithm’s outcome:
- If we pick , we would get to the optimum in one step
- If we pick , we would get a little closer in every step, eventually converging to
- If we pick , we are going to overshoot . Slightly bigger than 1 (say, 1.5) would still converge; would loop infinitely between two points; diverges.
Gradient descent for linear MSE
Our linear regression is given by a line that is a regression for some data :
We make predictions by multiplying the data by the weights, so our model is:
We define the error vector by:
The MSE can then be restated as follows:
And the gradient is, component-wise:
We’re using column notation to signify column of the matrix .
And thus, all in all, our gradient is:
To compute this expression, we must compute:
- The error , which takes floating point operations (flops) for the matrix-vector multiplication, and for the subtraction, for a total of , which is
- The gradient , which costs , which is .
In total, this process is at every step. This is not too bad, it’s equivalent to reading the data once.
Stochastic gradient descent (SGD)
In ML, most cost functions are formulated as a sum of:
In practice, this can be expensive to compute, so the solution is to sample a training point uniformly at random, to be able to make the sum go away.
The stochastic gradient descent step is thus:
Why is it allowed to pick just one instead of the full thing? We won’t give a full proof, but the intuition is that:
The gradient of a single n is:
Note that , and . Computational complexity for this is .
Mini-batch SGD
But perhaps just picking a single value is too extreme; there is an intermediate version in which we choose a subset instead of a single point.
Note that if then we’re performing a full gradient descent.
The computation of can be parallelized easily over GPU threads, which is quite common in practice; is thus often dictated by the number of available threads.
Computational complexity is .
Non-smooth (non-differentiable) optimization
We’ve defined convexity previously, but we can also use the following alternative characterization of convexity, for differentiable functions:
Meaning that the function must always lie above its linearization (which is the first-order Taylor expansion) to be convex.
Subgradients
A vector such that:
is called a subgradient to the function at . The subgradient forms a line that is always below the curve, somewhat like the gradient of a convex function.
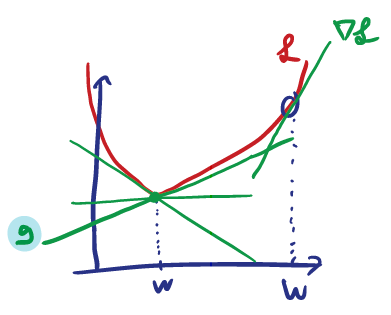
This definition is valid even for an arbitrary that may not be differentiable, and not even necessarily convex.
If the function is differentiable at , then the only subgradient at is .
Subgradient descent
This is exactly like gradient descent, except for the fact that we use the subgradient at the current iterate instead of the gradient:
For instance, MAE is not differentiable at 0, so we must use the subgradient.
Here, is somewhat confusing notation for the set of all possible subgradients at our position.
For linear regressions, the (sub)gradient is easy to compute using the chain rule.
Let be non-differentiable, differentiable, and . The chain rule tells us that, at , our subgradient is:
Stochastic subgradient descent
This is still commonly abbreviated SGD.
It’s exactly the same, except that is a subgradient to the randomly selected at the current iterate .
Comparison
| Smooth | Non-smooth | |
|---|---|---|
| Full gradient descent | Gradient of Complexity is |
Subgradient of Complexity is |
| Stochastic gradient descent | Gradient of | Subgradient of |
Constrained optimization
Sometimes, optimization problems come posed with an additional constraint.
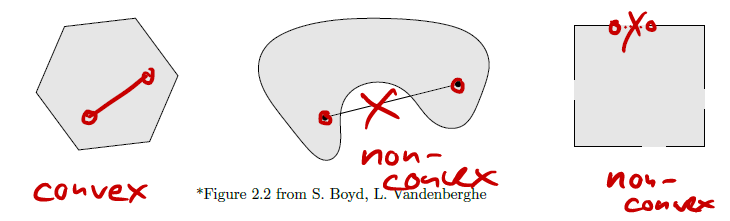
Convex sets
We’ve seen convexity for functions, but we can also define it for sets. A set is convex iff the line segment between any two points of lies in . That is, , we have:
This means that the line between any two points in the set must also be fully contained within the set.
A couple of properties of convex sets:
- Intersection of convex sets is also convex.
- Projections onto convex sets are unique (and often efficient to compute).
Projected gradient descent
When dealing with constrained problems, we have two options. The first one is to add a projection onto in every step:
The rule for gradient descent can thus be updated to become:
This means that at every step, we compute the new normally, but apply a projection on top of that. In other words, if the regular gradient descent sets our weights outside of the constrained space, we project them back.
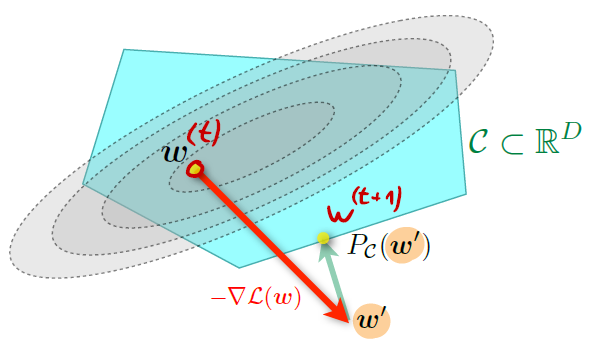
This is the same for stochastic gradient descent, and we have the same convergence properties.
Note that the computational cost of the projection is very important here, since it is performed at every step.
Turning constrained problems into unconstrained problems
If projection as described above is approach A, this is approach B.
We use a penalty function, such as the “brick wall” indicator function below:
We could also perhaps use something with a less drastic error value than , if we don’t care about the constraint quite as extreme.
Note that this is similar to regularization, which we’ll talk about later.
Now, instead of directly solving , we solve for:
Implementation issues in gradient methods
Stopping criteria
When is zero (or close to zero), we are often close to the optimum.
Optimality
For a convex optimization problem, a necessary condition for optimality is that the gradient is 0 at the optimum:
For convex functions, if the gradient is 0, then we’re at an optimum:
This tells us when is an optimum, but says nothing about whether it’s a minimum or a maximum. To know about that, we must look at the second derivative, or in the general case where , the Hessian. The Hessian is the matrix of second derivatives, defined as follows:
If the Hessian of the optimum is positive semi-definite, then it is a minimum (and not a maximum or a saddle point):
The Hessian is also related to convexity; it is positive semi-definite on its entire domain (i.e. all its eigenvalues are non-negative) if and only if the function is convex.
Step size
If is too big, we might diverge (as seen previously). But if it is too small, we might be very slow! Convergence is only guaranteed for , which is a value that depends on the problem.
Least squares
Normal equations
In some rare cases, we can take an analytical approach to computing the optimum of the cost function, rather than a computational one; for instance, for linear regression with MSE, as we’ve done previously. These types of equations are sometimes called normal equations. This is one of the most popular methods for data fitting, called least squares.
How do we get these normal equations?
First, we show that the problem is convex. If that is the case, then according to the optimality conditions for convex functions, the point at which the derivative is zero is the optimum:
This gives us a system of equations known as the normal equations.
Single parameter linear regression
Let’s try this for a single parameter linear regression (where ), with MSE as the cost function. We will start by accepting that the cost function is convex in the parameter3.
As proven previously, we know that for the single parameter model, the derivative is:
This means that the derivative is 0 for . This allows us to define our optimum parameter as .
Multiple parameter linear regression
Having done , let’s look at the general case where . As we know by now, the cost function for linear regression with MSE is:
Where the matrices are defined as:
We denote the row of by . Each represents a different data point.
We claim that this cost function is convex in . We can prove that in any of the following ways:
Simplest way
The cost function is the sum of many convex functions, and is thus also convex.
Directly verify the definition
The left-hand side of the inequality reduces to:
which indeed is .
Compute the Hessian
As we’ve seen previously, if the Hessian is positive semidefinite, then the function is convex. For our case, the Hessian is given by:
This is indeed positive semi-definite, as its eigenvalues are the squares of the eigenvalues of , and must therefore be positive.
Knowing that the function is convex, we can find the minimum. If we take the gradient of this expression, we get:
We can set this to 0 to get the normal equations for linear regression, which are:
This proves that the normal equations for linear regression are given by .
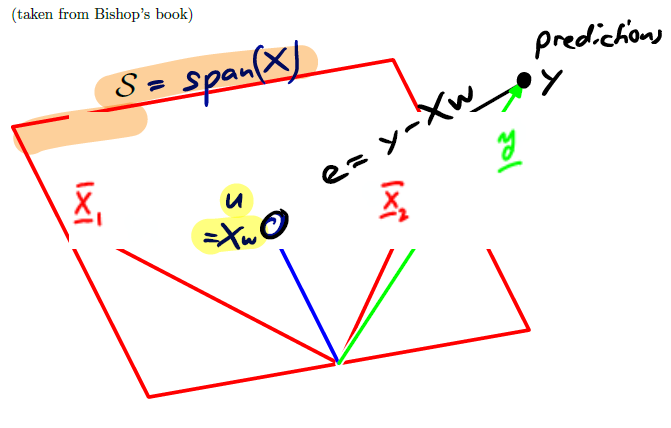
Geometric interpretation
The above definition of normal equations are given by . How can visualize that?
The error is given by:
By definition, this error vector is orthogonal to all columns of . Indeed, it tells us how far above or below the span our prediction is.
The span of is the space spanned by the columns of . Every element of the span can be written as for some choice of .
For the normal equations, we must pick an optimal for which the gradient is 0. Picking an is equivalent to picking an optimal from the span of .
But which element of shall we take, which one is the optimal one? The normal equations tell us that the optimum choice for , called is the element such that is orthogonal to .
In other words, we should pick to be the projection of onto .
Closed form
All we’ve done so far is to solve the same old problem of a matrix equation:
But we’ve always done so with a bit of a twist; there may not be an exact value of satisfying exact equality, but we could find one that gets us as close as possible:
This is also what least squares does. It attempts to minimize the MSE to get as close as possible to .
In this course, we often denote the data matrix as , the weights as , and as ; in other words, we’re trying to solve:
In least squares, we multiply this whole equation by on the left. We attempt to find , the minimal weight that gets us as minimally wrong as possible. In other we’re trying to solve:
One way to solve this problem would simply be to invert the matrix, which in our case is :
As such, we can use this model to predict values for unseen data points:
Invertibility and uniqueness
Note that the Gram matrix, defined as , is invertible if and only if has full column rank, or in other words, .
Unfortunately, in practice, our data matrix is often rank-deficient.
- If , we always have (since column and row rank are the same, which implies that ).
-
If , but some of the columns are collinear (or in practice, nearly collinear), then the matrix is ill-conditioned. This leads to numerical issues when solving the linear system.
To know how bad things are, we can compute the condition number, which is the maximum eigenvalue of the Gram matrix, divided by the minimum See course contents of Numerical Methods.
If our data matrix is rank-deficient or ill-conditioned (which is practically always the case), we certainly shouldn’t be inverting it directly! We’ll introduce high numerical errors that falsify our output.
That doesn’t mean we can’t do least squares in practice. We can still use a linear solver. In Python, that means you should use np.linalg.solve, which uses a LU decomposition internally and thus avoids the worst numerical errors. In any case, do not directly invert the matrix as we have done above!
Maximum likelihood
Maximum likelihood offers a second interpretation of least squares, but starting with a probabilistic approach.
Gaussian distribution
A Gaussian random variable in has mean and variance . Its distribution is given by:
For a Gaussian random vector, we have (instead of a single random variable in ). The vector has mean and covariance (which is positive semi-definite), and its distribution is given by:
As another reminder, two variables and are said to be independent when .
A probabilistic model for least squares
We assume that our data is generated by a linear model , with added Gaussian noise :
This is often a realistic assumption in practice.
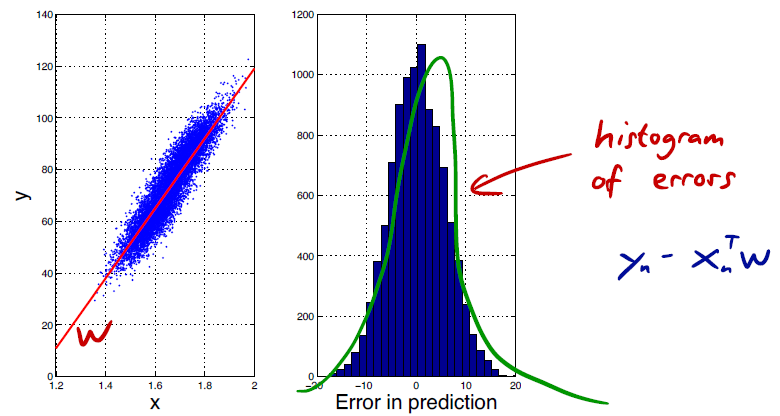
The noise is for each dimension . In other words, it is centered at 0, has a certain variance, and the error in each dimension is independent of that in other dimensions.
The model is, as always, unknown. But we can try to do a thought experiment: if we did know the model the data , in a system without the noise , we would know the labels with 100% certainty. The only thing that prevents that is the noise ; therefore, given the model and data, the probability distribution of seeing a certain is only given by all the noise sources . Since they are generated independently in each dimension, we can take the product of these noise sources.
Therefore, given samples, the likelihood of the data vector given the model and the input is:
Intuitively, we’d like to maximize this likelihood over the choice of the best model . The best model is the one that maximizes this likelihood.
Defining cost with log-likelihood
The log-likelihood (LL) is given by:
Taking the log allows us to get away from the nasty product, and get a nice sum instead. Notice that this definition looks pretty similar to MSE:
Note that we would like to minimize MSE, but we want the log-likelihood to be as high as possible (intuitively, we can look at the sign to understand that).
Maximum likelihood estimator (MLE)
Maximizing the log-likelihood (and thus the likelihood) will be equivalent to minimizing the MSE; this gives us another way to design cost functions. We can describe the whole process as:
The maximum likelihood estimator (MLE) can be understood as finding the model under which the observed data is most likely to have been generated from (probabilistically). This interpretation has some advantages that we discuss below.
Properties of MLE
MLE is a sample approximation to the expected log-likelihood. In other words, if we had an infinite amount of data, MLE would perfectly be equal to the true expected value of the log-likelihood.
This means that MLE is consistent, i.e. it gives us the correct model assuming we have enough data. This means it converges in probability4 to the true value:
MLE is asymptotically normal, meaning that the difference between the approximation and the true value of the weights converges in distribution4 to a normal distribution centered at 0, and with variance times the Fisher information of the true value:
Where the Fisher information5 is:
This sounds amazing, but the catch is that this all is under the assumption that the noise indeed was generated under a Gaussian model, which may not always be true. We’ll relax this assumption later when we talk about exponential families.
Overfitting and underfitting
Models can be too limited; when we can’t find a function that fits the data well, we say that we are underfitting. But on the other hand, models can also be too rich: in this case, we don’t just model the data, but also the underlying noise. This is called overfitting. Knowing exactly where we are on this spectrum is difficult, since all we have is data, and we don’t know a priori what is signal and what is noise.
Sections 3 and 5 of Pedro Domingos’ paper A Few Useful Things to Know about Machine Learning are a good read on this topic.
Underfitting with linear models
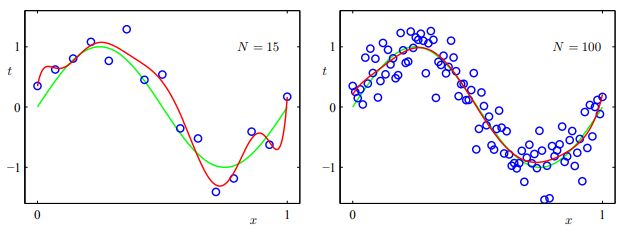
Linear models can very easily underfit; as soon as the data itself is given by anything more complex than a line, fitting a linear model will underfit: the model is too simple for the data, and we’ll have huge errors.
But we can also easily overfit, where our model learns the specificities of the data too intimately. And this happens quite easily with linear combination of high-degree polynomials.
Extended feature vectors
We can actually get high-degree linear combinations of polynomials, but still keep our linear model. Instead of making the model more complex, we simply “augment” the input to become degree . If the input is one-dimensional, we can add a polynomial basis to the input:
Note that this is basically a Vandermonde matrix.
We then fit a linear model to this extended feature vector :
Here, . In other words, there are parameters in a degree extended feature vector. One should be careful with this degree; too high may overfit, too low may underfit.
If it is important to distinguish the original input from the augmented input then we will use the notation. But often, we can just consider this as a part of the pre-processing, and simply write as the input, which will save us a lot of notation.
Reducing overfitting
To reduce overfitting, we can chose a less complex model (in the above, we can pick a lower degree ), but we could also just add more data:
Regularization
To prevent overfitting, we can introduce regularization to penalize complex models. This can be applied to any model.
The idea is to not only minimize cost, but also minimize a regularizer:
The function is the regularizer, measuring the complexity of the model. We’ll see some good candidates for the regularizer below.
-Regularization: Ridge Regression
The most frequently used regularizer is the standard Euclidean norm (-norm):
Where . The value of will affect the fit; can have overfitting, while can have underfitting.
The norm is given by:
The main effect of this is that large model weights will be penalized, while small ones won’t affect our minimization too much.
Ridge regression
Depending on the values we choose for and , we get into some special cases. For instance, choosing MSE for is called ridge regression, in which we optimize the following:
Least squares is also a special case of ridge regression, where
We can find an explicit solution for in ridge regression by differentiating the cost and regularizer, and setting them to zero:
We can now set the full cost to zero, which gives us the result:
Where . Note that for , we have the least squares solution.
Ridge regression to fight ill-conditioning
This formulation of is quite nice, because adding the identity matrix helps us get something that always is invertible; in cases where we have ill-conditioned matrices, it also means that we can invert with more stability.
We’ll prove that the matrix indeed is invertible. The gist is that the eigenvalues of are all at least .
To prove it, we’ll write the singular value decomposition (SVD) of as . We then have:
The singular value is “lifted” by an amount . There’s an alternative proof in the class notes, but we won’t go into that.
-Regularization: The Lasso
We can use a different norm as an alternative measure of complexity. The combination of -norm and MSE is known as The Lasso:
Where the -norm is defined as
If we draw out a constant value of the norm, we get a sort of “ball”. Below, we’ve graphed .
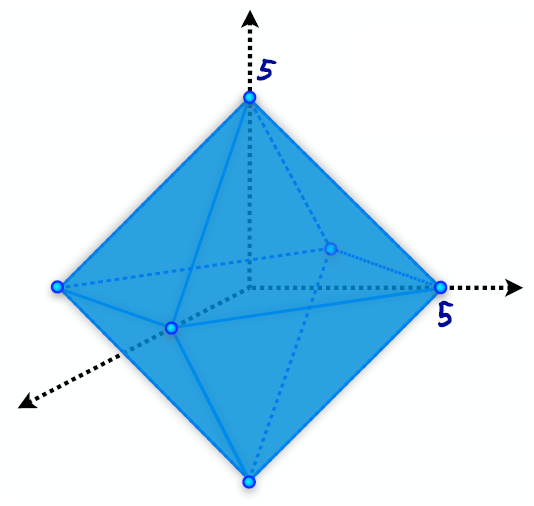
To keep things simple in the following, we’ll just claim that is invertible. We’ll also claim that the following set is an ellipsoid which scales around the origin as we change :
The slides have a formal proof for this, but we won’t get into it.
Note that the above definition of the set corresponds to the set of points with equal loss (which we can assume is MSE, for instance):
Under these assumptions, we claim that for regularization, the optimum solution will likely be sparse (many zero components) compared to regularization.
To prove this, suppose we know the norm of the optimum solution. Visualizing that ball, we know that our optimum solution will be somewhere on the surface of that ball. We also know that there are ellipsoids, all with the same mean and rotation, describing the equal error surfaces. The optimum solution is where the “smallest” of these ellipsoids just touches the ball.
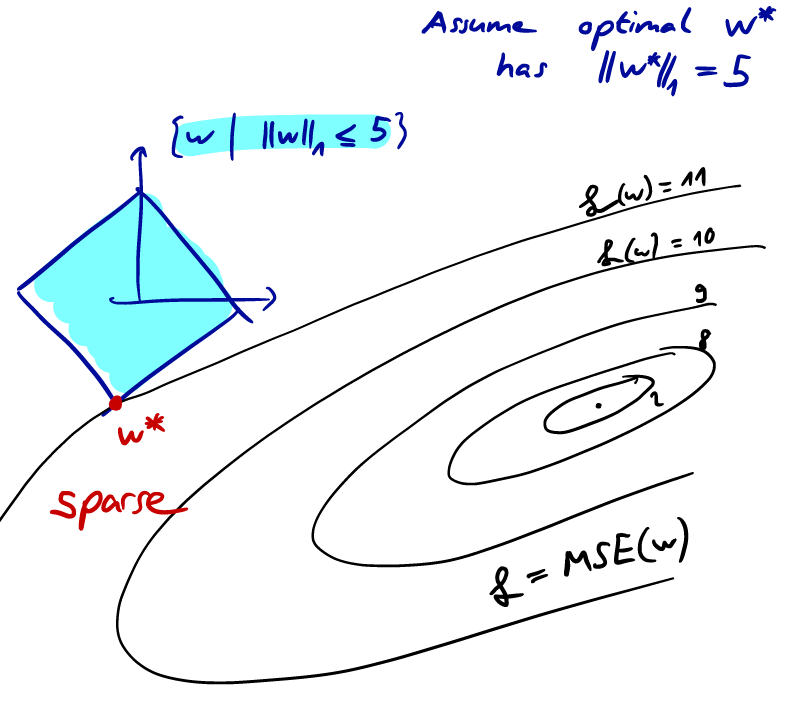
Due to the geometry of this ball this point is more likely to be on one of the “corner” points. In turn, sparsity is desirable, since it leads to a “simple” model.
Model selection
As we’ve seen in ridge regression, we have a regularization parameter that can be tuned to reduce overfitting by reducing model complexity. We say that the parameter is a hyperparameter.
We’ve also seen ways to enrich model complexity, like polynomial feature expansion, in which the degree is also a hyperparameter.
We’ll now see how best to choose these hyperparameters; this is called the model selection problem.
Probabilistic setup
We assume that there is an (unknown) underlying distribution producing the dataset, with range . The dataset we see is produced from samples from :
Based on this, the learning algorithm choses the “best” model using the dataset , under the parameters of the algorithm. The resulting prediction function is . To indicate that sometimes depend on hyperparameters, we can write the prediction function as .
Training Error vs. Generalization Error
Given a model , how can we assess if is any good? We already have the loss function, but its result is highly dependent on the error in the data, not to how good the model is. Instead, we can compute the expected error over all samples chosen according to .
Where is our loss function; e.g. for ridge regression, .
The quantity has many names, including generalization error (or true/expected error/risk/loss). This is the quantity that we are fundamentally interested in, but we cannot compute it since is unknown.
What we do know is the data subset6 . It’s therefore natural to compute the equivalent empirical quantity, which is the average loss:
But again, we run into trouble. The function is itself a function of the data , so what we really do is to compute the quantity:
is the trained model. This is called the training error. Usually, the training error is smaller than the generalization error, because overfitting can happen (even with regularization, because the hyperparameter may still be too low).
Splitting the data
To avoid validating the model on the same data subset we trained it on (which is conducive to overfitting), we can split the data into a training set and a test set (aka validation set), which we call and , so that . A typical split could be 80% for training and 20% for testing.
We apply the learning algorithm on the training set , and compute the function . We then compute the error on the test set, which is the test error:
If we have duplicates in our data, then this could be a bit dangerous. Still, in general, this really helps us with the problem of overfitting since is a “fresh” sample, which means that we can hope that defined above is close to the quantity . Indeed, in expectation both are the same:
The subscript on the expectation means that the expectation is over samples of the test set, and not for a particular test set (which could give a different result due to the randomness of the selection of ).
This is a quite nice property, but we paid a price for this. We had to split the data and thus reduce the size of our training data. But we will see that this can be mediated using cross-validation.
Generalization error vs test error
Assume that we have a model and that our loss function is bounded in . We are given a test set chosen i.i.d. from the underlying distribution .
How far apart is the empirical test error from the true generalization error? As we’ve seen above, they are the same in expectation. But we need to worry about the variation, about how far off from the true error we typically are:
We claim that:
Where is a quality parameter. This gives us an upper bound on how far away our empirical loss is from the true loss.
This bound gives us some nice insights. Error decreases in the size of the test set as , so the more data points we have, the more confident we can be in the empirical loss being close to the true loss.
We’ll prove . We assumed that each sample in the test set is chosen independently. Therefore, given a model , the associated losses are also i.i.d. random variables, taking values in by assumption. We can call each such loss :
This is just a naming alias; since the underlying value is that of the loss function, the expected value of is simply that of the loss function, which is the true loss:
The empirical loss on the other hand is equal to the average of such i.i.d. values.
The formula of gives us the probability that empirical loss diverges from the true loss by more than a given constant, which is a classical problem addressed in the following lemma (which we’ll just assert, not prove).
Chernoff Bound: Let be a sequence of i.i.d random variables with mean and range . Then, for any :
Using we can show . By setting , we find that as claimed.
Method and criteria for model selection
Grid search on hyperparameters
Our main goal was to look for a way to select the hyperparameters of our model. Given a finite set of values for of a hyperparameter , we can run the learning algorithm times on the same training set , and compute the prediction functions . For each such prediction function we compute the test error, and choose the which minimizes the test error.
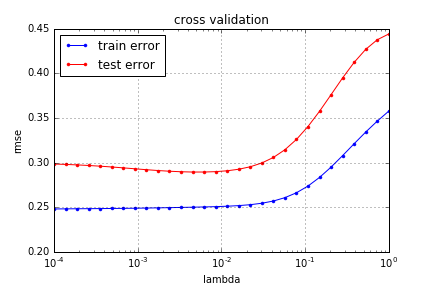
This is essentially a grid search on using the test error function.
Model selection based on test error
How do we know that, for a fixed function , is a good approximation to ? If we’re doing a grid search on hyperparameters to minimize the test error , we may pick a model that obtains a lower test error, but that may increase .
We’ll therefore try to see how much the bound increases if we pick a false positive, a model that has lower test error but that actually strays further away from the generalization error.
The answer to this follows the same idea as when we talked about generalization vs test error, but we now assume that we have models for . We assume again that the loss function is bounded in , and that we’re given a test set whose samples are chosen i.i.d. in .
How far is each of the (empirical) test errors from the true ? As before, we can bound the deviation for all candidates, by:
A bit of intuition of where this comes from: for a general , we check the deviations for independent samples and ask for the probability that for at least one such sample we get a deviation of at least (this is what the bound answers). Then by the union bound this probability is at most times as large as in the case where we are only concerned with a single instance. Thus the upper bound in Chernoff becomes , which gives us as above.
As before, this tells us that error decreases in .
However, now that we test hyperparameters, our error only goes up by a tiny amount of . This follows from , which we proved for the special case of . So we can reasonably do grid search, knowing that in the worst case, the error will only increase by a tiny amount.
Cross-validation
Splitting the data once into two parts (one for training and one for testing) is not the most efficient way to use the data. Cross-validation is a better way.
K-fold cross-validation is a popular variant. We randomly partition the data into groups, and train times. Each time, we use one of the groups as our test set, and the remaining groups for training.
To get a common result, we average out the results. This means we’ll use the average weights to get the average test error over the folds.
Cross-validation returns an unbiased estimate of the generalization error and its variance.
Bias-Variance decomposition
When we perform model selection, there is an inherent bias–variance trade-off.
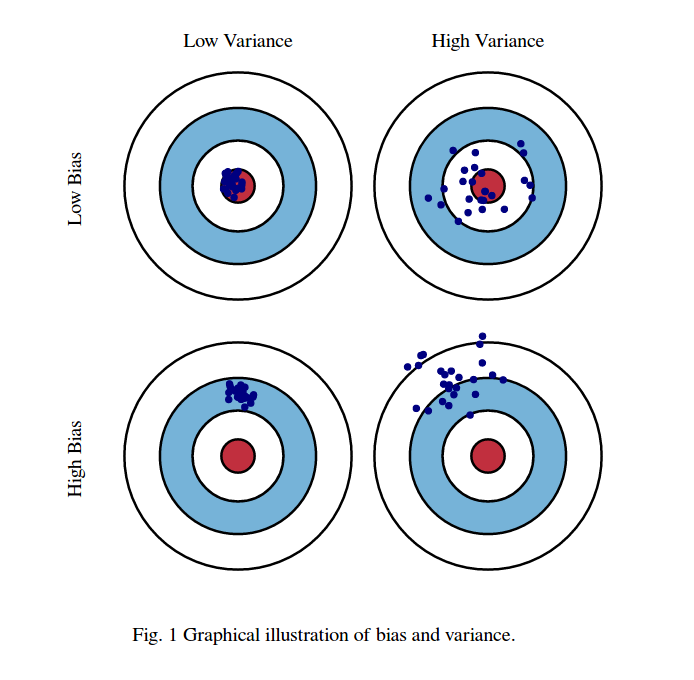
If we were to build the same model over and over again with re-sampled datasets, our predictions would change because of the randomness in the used datasets. Bias tells us how far off from the correct value our predictions are in general, while variance tells us about the variability in predictions for a given point in-between realizations of the models.
For now, we’ll just look at “high-bias & low-variance” models, and “high-variance & low-bias” models.
- High-bias & low-variance: the model is too simple. It’s underfit, has a large bias, and and the variance of is small (the variations due to the random sample ).
- High-variance & low-bias: the model is too complex. It’s overfit, has a small bias and large variance of (the error depends largely on the exact choice of ; a single addition of a data point is likely to change the prediction function considerably)
Consider a linear regression with one-dimensional input and polynomial feature expansion of degree . The former can be achieved by picking a too low value for , while the latter by picking too high. The same principle applies for other parameters, such as ridge regression with hyperparameter .
Data generation model
Let’s assume that our data is generated by some arbitrary, unknown function , and a noise source with distribution (i.i.d. from sample to sample, and independent from the data). We can think of representing the precise, hypothetical function that perfectly produced the data. We assume that the noise has mean zero (without loss of generality, as a non-zero mean could be encoded into ).
We assume that is generated according to some fixed but unknown distribution . We’ll be working with square loss . We will denote the joint distribution on pairs as .
Error Decomposition
As always, we have a training set , which consists of i.i.d. samples from . Given our learning algorithm , we compute the prediction function . The square loss of a single prediction for a fixed element is given by the computation of:
Our experiment was to create , learn , and then evaluate the performance by computing the square loss for a fixed element . If we run this experiment many times, the expected value is written as:
This expectation is over randomly selected training sets of size , and over noise sources. We will now show that this expression can be rewritten as a sum of three non-negative terms:
Note that here, is a second training set, also sampled from , that is independent of the training set . It has the same expectation, but it is different and thus produces a different trained model .
Step uses as well as linearity of expectation to produce . Note that the part is zero as the noise is independent from .
Step uses the definition of variance as:
Seeing that our noise has mean zero, we have and therefore .
In step , we add and subtract the constant term to the expression like so:
We can then expand the square , where becomes the bias, and the variance. We can drop the expectation around as it is over , while is only defined in terms of , which is independent from . The part of the expansion is zero, as we show below:
In the first step, we can pull out of the expectation as it is a constant term with regards to . The same reasoning applies to in the second step. Finally, we get zero in the third step by realizing that:
Interpretation of the decomposition
Each of the three terms in non-negative, so each of them is a lower bound on the expected loss when we predict the value for the input .
- When the data contains noise, then that imposes a strict lower bound on the error we can achieve.
- The bias term is a non-negative term that tells us how far we are from the true value, in expectation. It’s the square loss between the true value and the expected prediction , where the expectation is over the training sets. As we discussed above, with a simple model we will not find a good fit on average, which means the bias will be large, which adds to the error we observe.
- The variance term is the variance of the prediction function. For complex models, small variations in the data set can produce vastly different models, and our prediction will vary widely, which also adds to our total error.
Classification
When we did regression, our data was of the form:
With classification, our prediction is no longer discrete. Now, . If it can only take two values (i.e. ), then it is called binary classification. If it can take more than two values, it is multi-class classification.
There is no ordering among these classes, so we may sometimes denote these labels as .
If we knew the underlying distribution , then it would be clear how we could measure the probability of error. We have a correct prediction when , and an incorrect one otherwise, so:
Where is an indicator function that returns 1 when the condition is correct, and 0 otherwise. If we don’t know the distribution, we could just take an empirical sum, and use that instead.
A classifier will divide the input space into a collection of regions belonging to each class; the boundaries are called decision boundaries.
Linear classifier
A linear classifier splits the input with a line in 2D, a plane in 3D, or more generally, a hyperplane. But a linear classifier can also classify more complex shapes if we allow for feature augmentation. For instance (in 2D), if we augment the input to degree and a constant factor, our linear classifier can also detect ellipsoids. So without loss of generality, we’ll simply study linear classifiers and allow feature augmentation, without loss of generality.
Is classification a special case of regression?
From the initial definition of classification, we see that it is a special case of regression, where the output is restricted to a small discrete set instead of a continuous spectrum.
We could construct classification from regression by simply rounding to the nearest value. For instance, if we have , we can use (regularized) least-squares to learn a prediction function for this regression problem. We can then convert the regression to a classification by rounding: we decide on if and if .
But this is somewhat questionable as an approach. MSE penalizes points that are far away from the result before rounding, even though they would be correct after rounding.
This means that if we have a small loss with MSE, we can guarantee a small classification error (as before), but crucially, the opposite is not true: a regression function can have very high MSE though the classification error is very very small.
It also means that the regression line will likely not be very good. With MSE, the “position” of the line defined by will depend crucially on how many points are in each class, and where the points lie. This is not desirable for classification: instead of minimizing the cost function, we’d like for the fraction of misclassified cases to be small. The mean-squared error turns out to be only loosely related to this.
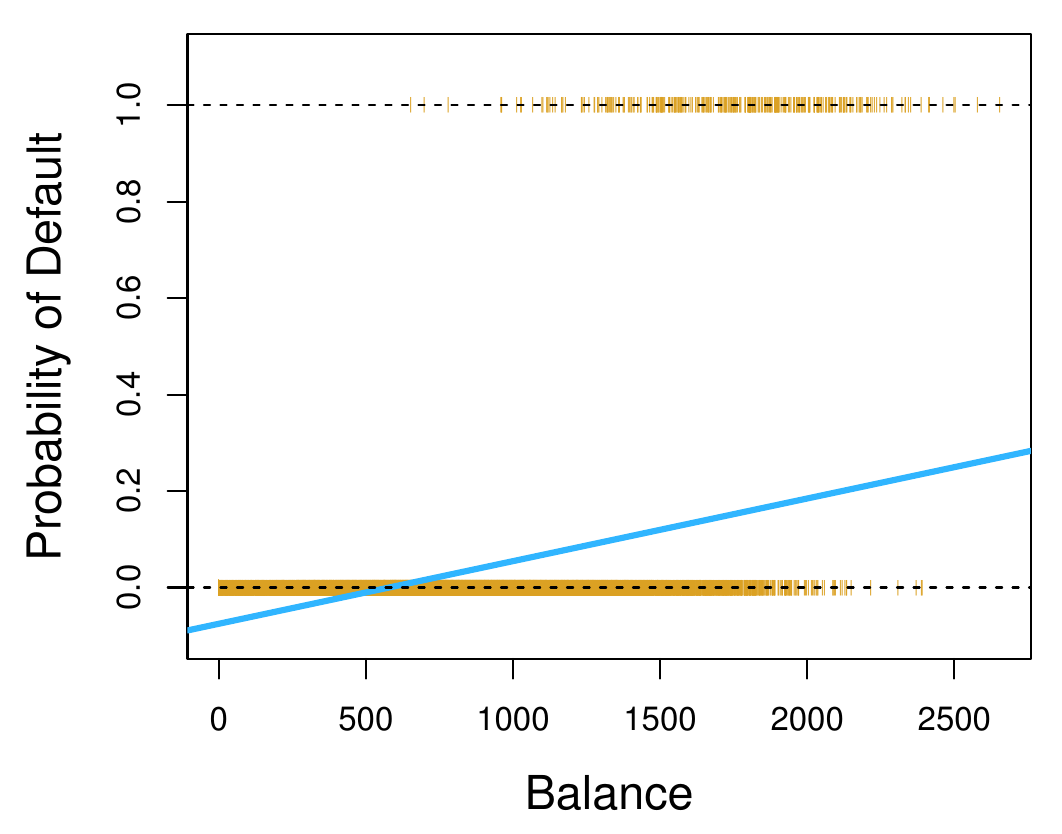
So instead of building classification as a special case of regression, let’s take a look at some basic alternative ideas to perform classification.
Nearest neighbor
In some cases it is reasonable to postulate that there is some spatial correlations between points of the same class: inputs that are “close” are also likely to have the same label. Closeness may be measured by Euclidean distance, for instance.
This can be generalized easily: instead of taking the single nearest neighbor, a process very prone to being swayed by outliers, we can take the nearest neighbors (which we’ll talk about later in the course), or a weighted linear combination of elements in the neighborhood (smoothing kernels, which we won’t talk about).
But this idea fails miserably in high dimensions, where the geometry renders the idea of “closeness” meaningless. High-dimensional space is a very lonely place; in a high-dimensional space, if we grow the area around a point, we’re likely to see no one for a very long time, and then once we get close to the boundaries of the space, 💥, everyone is there at once. This is known as the curse of dimensionality.
The idea also fails when we have too little data, especially in high dimensions, where the closest point may actually be far away and a very bad indicator of the local situation.
Linear decision boundaries
As a starting point, we can assume that decision boundaries are linear (hyperplanes). To keep things simple, we can assume that there is a separating hyperplane, i.e. a hyperplane so that no point in the training set is misclassified.
There may be many such lines, so which one do we pick? This may be a little hand-wavy, but the intuition is the most “robust”, or the one that offers the greatest “margin”: we want to be able to “wiggle” the inputs (by changing the training set) as much as possible while keeping the numbers of misclassifications low. This idea will lead us to support vector machines (SVMs).
But the linear decision boundaries are limited, and in many cases too strong of an assumption. We can augment the feature vector with some non-linear functions, which is what we do with the kernel trick, which we will talk about later. Another option is to use neural networks to find an appropriate non-linear transform of the inputs.
Optimal classification for a known generating model
To find a solution, we can gain some insights if we assume that we know the joint distribution that created the data (where takes values in a discrete set ). In practice, we don’t know the model, but this is just a thought experiment. We can assume that the data was generated from a model , where , where is noise.
Given the fact that there is noise, a perfect solution may not always be possible. But if we see an input , how can we pick an optimal choice for this distribution? We want to maximize the probability of guessing the correct label, so we should choose according to the rule:
This is known as the maximum a-posteriori (MAP) criterion, since we maximize the posterior probability (the probability of a class label after having observed the input).
The probability of a correct guess is thus the average over all inputs of the MAP, i.e.:
In practice we of course do not know the joint distribution, but we could use this approach by using the data itself to learn the distribution (perhaps under the assumption that it is Gaussian, and just fitting the and parameters).
Logistic regression
Recall that we discussed what happens if we look at binary classification as a regression. We also discussed that it is tempting to look at the predicted value as a probability (i.e. if the regression says 0.8, we could interpret it as 80% certainty of and 20% probability of ). But this leads to problems, as the predicted values may not be in , even largely surpassing these bounds, and this contributes to the error in MSE even though they indicate high certainty.
So the natural idea is to transform the prediction, which can take values in , into a true probability in . This is done by applying an appropriate function7, one of which is the logistic function, or sigmoid function8:
How do we use this? Let’s consider binary classification, with labels 0 and 1. Given a training set, we learn a weight vector . Given a new feature vector , the probability of the class labels given are:
This allows us to predict a certainty, which is a real value and not a label, which is why logistic regression is called regression, even though it is still part of a classification scheme. The second step of the scheme would be to quantize this value to a binary value. For binary classification, we’d pick 0 if the value is less than 0.5, and 1 otherwise.
Training
To train the classifier, the intuition is that we’d like to maximize the likelihood of our weight vector explaining the data:
We know that maximizing the likelihood is consistent, it gives us the correct model assuming we have enough data. Using the chain rule for probabilities, the probability becomes:
As we’re trying to get the argmax over the weights, we can discard as it doesn’t depend on . Therefore:
Using the fact that the samples in the dataset are independent, and given the above formulation of the prior, we can express the maximum likelihood criterion (still for the binary case )
But this product is nasty, so we’ll remove it by taking the log. We also multiply by , which means we also need to be careful about taking the minimum instead of the maximum. The resulting cost function is thus:
Conditions of optimality
As we discuss above, we’d like to minimize the cost . Let’s look at the stationary points of our cost function by computing its gradient and setting it to zero.
It just turns out that taking the derivative of the logarithm in the inner part of the sum above gives us the logistic function:
Therefore, the whole derivative is:
The matrix is ; both and are column vectors of length . Therefore, to simplify notation, we let represent element-wise application of the sigmoid function on the size vector resulting from .
There is no closed-form solution for this, so we’ll discuss how to solve it in an iterative fashion by using gradient descent or the Newton method.
Gradient descent
is convex in the weight vector . We can therefore do gradient descent on this cost function as we’ve always done:
Newton’s method
Gradient descent is a first-order method, using only the first derivative of the cost function. We can get a more powerful optimization algorithm using the second derivative. This is based on the idea of Taylor expansions. The 2nd order Taylor expansion of the cost, around , is:
Where denotes the Hessian, the symmetric matrix with entries:
Hessian of the cost
Let’s compute this Hessian matrix. We’ve already computed the gradient of the cost function in the section above, where saw that the gradient of a single term is:
Each term only depends on in the term. Therefore, the Hessian associated to one term is:
Given that the derivative of the sigmoid is , by the chain rule, each term of the sum gives rise to the Hessian:
This is the Hessian for a single term; if we sum up over all terms, we get to the following matrix product:
The matrix is diagonal, with positive entries, which means that the Hessian is positive semi-definite, and therefore that the problem indeed is convex. The entries are:
Closed form for Newton’s method
In this model, we’ll assume that the Taylor expansion above denotes the cost function exactly instead of approximately. In other words, we’re assuming strict equality instead of approximation as above. This is only an assumption; it isn’t strictly true, but it’s a decent approximation. Where does this take minimum value? To know that, let’s set the gradient of the Taylor expansion to zero. This yields:
If we solve for , this gives us an iterative algorithm for finding the optimum:
The trade-off for the Newton method is that while we need fewer iterations, each of them is more costly. In practice, which one to use depends, but at least we have another option with the Newton method.
Regularized logistic regression
If the data is linearly separable, there is no finite-weight vector. Running the iterative algorithm will make the weights diverge to infinity. To avoid this, we can regularize with a penalty term.
Generalized Linear Models
Previously, with least squares, we assumed that our data was of the form:
This is a D-linear model. When talking about generalized linear models, we’re still talking about something linear, but we allow the noise to be something else than a Gaussian distribution.
Motivation
The motivation for this is that while standard logistic regression only allows for binary outputs9, we may want to have something equivalently computationally efficient for, say, . To do so, we introduce a different class of distributions, called the exponential family, with which we can revisit logistic regression and get other properties.
This will be useful in adding a degree of freedom. Previously, we most often used linear models, in which we model the data as a line, plus zero-mean Gaussian noise. As we saw, this leads to least squares. When the data is more complex than a simple line, we saw that we could augment the features (e.g. with , ), and still use a linear model. The idea was to augment the feature space . This gave us an added degree of freedom, and allowed us to use linear models for higher-degree problems.
These linear models predicted the mean of the distribution from which we assumed the data to be sampled. When talking about mean here, we mean what we assume the data to be modeled after, without the noise. In this section, we’ll see how we can use the linear model to predict a different quantity than the mean. This will allow us to add another degree of freedom, and use linear models to get other predictions than just the shape of the data.
We’ve actually already done this, without knowing it. In (binary) logistic regression, the probability of the classes was:
We’re using as a shorthand for , and will do so in this section. More compactly, we can write this in a single formula:
Note that the linear model does not predict the mean, which we’ll denote (don’t get confused by this notation; in this section, is not a scalar, but represents the “real values” that the data is modeled after, without the noise). Instead, our linear model predicts , which is transformed into the mean by using the function:
This relation between and is known as the link function. It is a nonlinear function that makes it possible to use a linear model to predict something else than the mean .
Exponential family
In general, the form of a distribution in the exponential family is:
Let’s take a look at the various components of this distribution:
- is called a sufficient statistic. It’s usually a vector. Its name stems from the fact that its empirical average is all we need to estimate
- is the log-partition function, or the cumulant.
The domain of can be vary: we could choose , , , etc. Depending on this, we may have to do sums or integrals in the following.
We require that the probability be non-negative, so we need to ensure that . Additionally, a probability distribution needs to integrate to 1, so we also require that that:
This can be rewritten to:
The role of is thus only to ensure a proper normalization. To create a member of the exponential family, we can choose the factor , the vector and the parameter ; the cumulant is then determined for each such choice, and ensures that the expression is properly normalized. From the above, it follows that is defined as:
We exclude the case where the integral is infinite, as we cannot compute a real for that case.
Link function
There is a relationship between the mean and using the link function :
The link function is a 1-to-1 transformation from the usual parameters (e.g. for Gaussian distributions) to the natural parameters (e.g. for Gaussian distributions).
For a list of such functions, consult the chapter on Generalized Linear Models in the KPM book.
Example: Bernoulli
The Bernoulli distribution is a member of the exponential family. Its probability density is given by:
The parameters are thus:
Here, is a scalar, which means that the family only depends on a single parameter. Note that and are linked:
The link function is the same sigmoid function we encountered in logistic regression.
Example: Poisson
The Poisson distribution with mean is given by:
Where the parameters of the exponential family are given by:
Example: Gaussian
Notation for Gaussian distributions can be a little confusing, so we’ll make sure to distinguish the notation of the usual parameter vectors (in bold), from the parameters themselves, which are the Gaussian mean and variance .
The density of a Gaussian is:
There are two parameters to choose in a Gaussian, and , so we can expect something of degree 2 in exponential form. Let’s rewrite the above:
Where:
Indeed, this time is a vector of dimension 2, which reflects that the distribution depends on 2 parameters. As the formulation of shows, we have a 1-to-1 correspondence to and the parameters:
Properties
- is convex
Proofs for the first 3 properties are in the lecture notes. The last property is given without proof.
Application in ML
We use , or equivalently, .
Maximum Likelihood Parameter Estimation
Assume that we have samples composing our training set, i.i.d. from some distribution, which we assume is some exponential family. Assume we have picked a model, i.e. that we fixed and , but that is unknown. How can we find an optimal ?
We said previously that is a sufficient statistic, and that we could find from its empirical average; this is what we’ll do here. We can use the maximum likelihood principle to find this parameter, meaning that we want to minimize log-likelihood:
This is a convex function in : the term does not depend on , is linear, has the property of being convex.
If we assume that we have the link function already, we can get by setting the gradient of our exponential family to 0. We also multiply by to get a more convenient form, i.e. with instead of :
Since , we get:
Therefore, we can get by using the link function:
With this, we can see the justification for calling a sufficient statistic.
Conditions of optimality
If we assume that our samples follow the distribution of an exponential family, we can construct a generalized linear model. As we’ve explained previously, this is a generalization of the model we used for logistic regression.
For such a model, the maximum likelihood problem, as described above, is easy to solve. As we’ve noted above, the cost function is convex, so a greedy, iterative algorithm should work well. Let’s look at the gradient of the cost in terms of (instead of as previously):
Let’s recall that the derivative of the cumulant is:
Hence the gradient of the cost function is:
Setting this to zero gives us the condition of optimality. Using matrix notation, we can rewrite this sum as follows:
Note that this is a more general form of the formula we had for logistic regression. At this point, seeing that the function is convex, we can use a greedy iterative algorithm like gradient descent to find the minimum.
Nearest neighbor classifiers and the curse of dimensionality
For simplicity, let’s assume that we’re operating in a d-dimensional box, that is, in the domain . As always, we have a training set .
K Nearest Neighbor (KNN)
Given a “fresh” input , we can make a prediction using . This is a set of the inputs in the training set that are closest to .
For the regression problem, we can take the average of the k nearest neighbors:
For binary classification, we take the majority element in the -neighborhood. It’s a good idea to pick to be odd so that there is a clear winner.
If we pick a large value of , then we are smoothing over a large area. Therefore, a large gives us a simple model, with simpler boundaries, while a small is a more complex model. In other words, complexity is inversely proportional to . As we saw when we talked about bias and variance, if we pick a small value of we can expect a small bias but huge variance. If we pick a large we can expect large bias but small variance.
Analysis
We’ll analyze the simplest setting, a binary KNN model (that is, there are only two output labels, 0 and 1). Let’s start by simplifying our notation. We’ll introduce the following function:
This is the conditional probability that the label is 1, given that the input is . If this probability is to be meaningful at all, we must have some correlation between the “position” x and the associated label; knowing the labels close by must give us some information. This means that we need an assumption on the distribution :
On the right-hand side we have Euclidean distance. In other words, we ask that the conditional probability , denoted by , be Lipschitz continuous with Lipschitz constant . We will use this assumption later on to prove a performance bound for our KNN model.
Let’s assume for a moment that we know the actual underlying distribution. This is not something that we actually know in practice, but is useful for deriving a formulation for the optimal model. Knowing the distribution probability distribution, our optimum decision rule is given by the classifier:
The idea of this classifier is that with two labels, we’ll pick the label that is likely to happen more than half of the time. The intuition is that if we were playing heads or tails and knew the probability in advance, we would always pick the option that has probability more than one half, and that is the best strategy we can use. This is known as the Bayes classifier, also called maximum a posteriori (MAP) classifier. It is optimal, in that it has the smallest probability of misclassification of any classifier, namely:
Let’s compare this to the probability of misclassification of the real model:
This tells us that the risk (that is, the error probability of our nearest neighbor classifier) is the above expectation. It’s hard to find a closed form for that expectation, but we can place a bound on it by comparing the ideal, theoretical model to the actual model. We’ll state the following lemma:
Before we see where this comes from, let’s just interpret it. The above gives us a bound on the real classifier, compared to the optimal one. The actual classifier is upper bounded by twice the risk of the optimal classifier (this is good), plus a geometric term reflecting dimensionality (it depends on : this will cause us some trouble).
This second term of the sum is the average distance of a randomly chosen point to the nearest point in the training set, times the Lipschitz constant . It intuitively makes sense to incorporate this factor into our bound: if we are basing our prediction on a point that is very close, we’re more likely to be right, and if it’s far away, less so. If we’re in a box of , then the distance between two corners would be (by Pythagoras’ theorem). The term indicates that the closest data point may be closer than the opposite corner of the cube: if we have more data, we’ll probably not have to go that far. However, for large dimensions, we need much more data to have something that’ll probably be close.
Let’s prove where this geometric term comes from by considering the cube , the space of inputs containing . We can cut this large cube into small cubes of side length . Consider the small cube containing . If we are lucky, this small cube also contains a neighboring data point at distance at most (at the opposite corner of the small cube; we use Pythagoras’ theorem as above). However, if we’re less lucky, the closest neighbor may be at the other corner of the big cube, at distance . So what is the probability of a point not having a neighbor in its small cube?
Let’s denote the probability of landing in a particular box by . The chance that none of the N training points are in the box is . We don’t know the distribution , so we can’t really express in a closed form, but that doesn’t matter, this notation allows us to abstract over that. The rest of the proof is calculus, carefully choosing the right scaling for in order to get a good bound.
Now, let’s understand where the term comes from. If we flip two coins, and , what is the probability of the outcome being different?
Now, let’s consider two points and , both elements of . Their labels are and , respectively. The probability of these two labels being different is roughly the same as above (although the probabilities of the two events may not be the same in general):
The second to last step uses the fact that is a probability distribution, so . The last step uses the .
Therefore, we can confirm the following bound:
But we are still one step away from explaining how we can compare this to the optimal estimator. In the above, we derived a bound for two labels being different. How is this related to our KNN model? The probability of getting a wrong prediction from KNN with (which we denoted ) is the probability of the predicted label being different from the solution label.
We get to our lemma by the following reasoning:
Additionally, the average of the term is
If we had assumed that it was a ball instead of a cube, we would’ve gotten slightly different results. But that’s besides the point: the main insight from this is that it depends on the dimension, and that for low dimensions at least, we still have a fairly good classifier. But finding a closest neighbor in high dimension can quickly become meaningless.
Support Vector Machines
Definition
Let’s re-consider binary classification. In the following it will be more convenient to consider . This is equivalent to what we’ve done previously, under the mapping and . Note that this mapping can be done continuously in the range by computing , and back with .
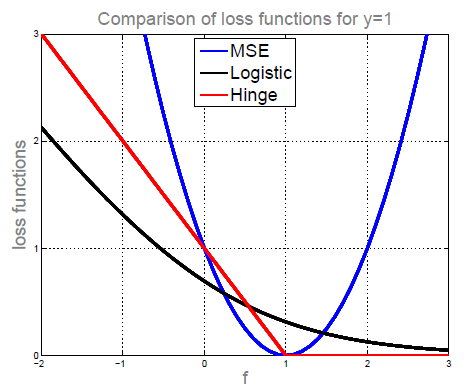
Previously, we used MSE or logistic loss. MSE is symmetric, so something being positive or negative is punished at an equal rate. With logistic regression, we always have a loss, but its value is asymmetric, shrinking the further we go right.
If we instead use hinge loss (as defined below), with an additional regularization term, we get Support Vector Machines (SVM).
Here, we use as shorthand for . The function multiplies the prediction with the actual label, which produces a positive result if they are of the same sign, and a negative result if they have different signs (this is why we wanted our labels in ). When the prediction is correct and above one, becomes negative, and hinge loss returns 0. This makes hinge loss a linear function when predictions are incorrect or below one; it does not punish correct predictions above one, which pushes us to give predictions that we can be very confident about (above one).
SVMs correspond to the following optimization problem:
What does this optimization problem correspond to, intuitively?
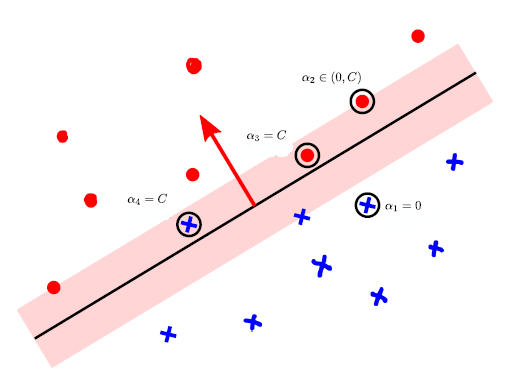
In the figure above, the pink region represents the “margin” created by the SVM. The center of the margin is the separating hyperplane; its direction is perpendicular to , the normal vector defining the hyperplane. The margin’s total width is .
Points inside the margin are feature vectors for which . These points incur a cost with hinge loss. Any points outside the margin, for which , do not incur any cost, as long as they’re on the correct side. Thus, depending on the that we choose, the orientation and size of the margin will change; there will be a different number of points in it, and the cost will change.
How can we pick a good margin? Let’s assume is small; we won’t define that further, the main point is just we pick one with the following priorities (in order):
- We want a separating hyperplane
- We want a scaling of so that no point of the data is in the margin
- We want the margin to be as wide as possible
With conditions 1 and 2, we can ensure that there is no cost incurred in the first expression (the sum over ). The third condition is ensured by the fact that we’re minimizing . Since the size of the margin is inversely proportional to that, we’re maximizing the margin.
We’ve introduced SVMs for the general case, where the data is not necessarily linearly separable, which is the soft-margin formulation. In the hard-margin formulation, the data is linearly separable by a separating hyperplane. Maximizing the margin size in the hard-margin formulation implies that some points will lie exactly on the margin boundary (on the correct side). These points are called essential support vectors. For the soft-margin case, this interpretation becomes a little more muddled.
Alternative formulation: Duality
Now that we know what function we’re optimizing, let’s look at how we can optimize it efficiently. The function is convex, and has a subgradient in , which means we can use SGD with subgradients. This is good news! We’ll discuss an alternative, but equivalent formulation via the concept of duality, which can lead us to a more efficient implementation in some cases. More importantly though, the dual problem can point us to a more general formulation, called the kernel trick.
Let’s say that we’re interested in minimizing a cost function . Let’s assume this can be defined through an auxiliary function , such that:
The minimization in question is thus:
We call this the primal problem. In some cases though, it may be easier to find this in the other direction:
We call this the dual problem. This leads us to a few questions:
How do we find a suitable function G?
There’s a general theory on this topic (see Nonlinear Programming by Dimitri Bertsekas). In the case of SVMs though, the finding the function G is rather straightforward, once we restate the hinge loss as follows:
The SVM problem then becomes:
Note that G is convex in , and linear, hence concave, in .
When is it OK to switch min and max?
It is always true that:
This is proven by:
Equality is achieved when the function looks like a saddle: when is a continuous function that is convex in , concave in , and the domains of both are compact and convex.
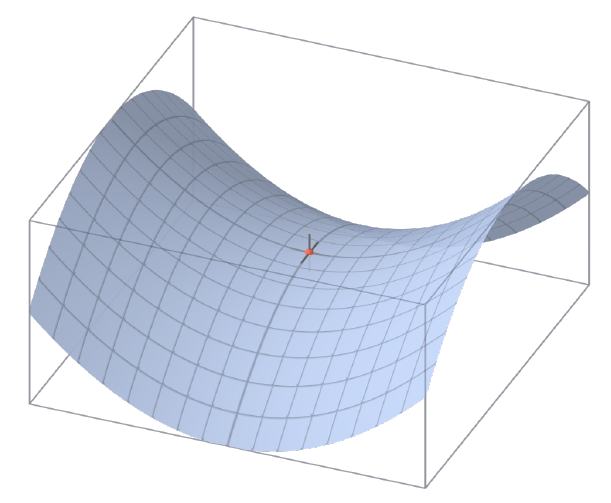
For SVMs, this condition is fulfilled, and the switch between min and max can be done. The alternative formulation of SVMs is:
We can take the derivative with respect to :
We’ll set this to zero to find a formulation of in terms of . We get:
Where . If we plug this into , we get the following dual problem, in quadratic form:
When is the dual easier to optimize than the primal?
- When the dual is a differentiable quadratic problem (as SVM is). This is a problem that takes the same as above. In this case, we can optimize by using coordinate descent (or more precisely, ascent, as we’re searching for the maximum). Crucially, this method only changes one variable at a time.
- In the above, the data enters the formula in the form . This is called the kernel. We say this formulation is kernelized. Using this representation is called the kernel trick, and gives us some nice consequences that we’ll discuss later.
- Typically, the solution is sparse, being non-zero only in the training examples that are instrumental in determining the decision boundary. If we recall how we defined in an alternative formulation of , we can see that there are three distinct cases to consider:
- Examples that lie on the correct side, and outside the margin, for which . These are non-support vectors
- Examples that are on the correct side and just on the margin, for which , so . These are essential support vectors
- Examples that are strictly within the margin, or on the wrong side have , and are called bound support vectors
Kernel trick
We saw previously that our data only enters in the form of a kernel, . We’ll see now that when we’re using the kernel, we can easily go to a much larger dimensional space (even infinite dimensional space) without adding any complexity. This isn’t always applicable though, so we’ll also see which kernel functions are admissible for this trick.
Alternative formulation of ridge regression
Let’s recall that least squares is a special case of ridge regression (where ). Ridge regression corresponds to the following optimization problem:
We saw that the solution has a closed form:
We claim that this can be alternatively written as:
The original formulation’s runtime is , while the alternative is . Which is more efficient depends on and .
Proof
We can prove this formulation by using the following identity. If we let be an matrix, and be . Then:
Assuming that and are invertible, we have the identity:
To derive the formula, we can let and .
Representer theorem
The representer theorem generalizes what we just saw about ridge regression. For a minimizing the following, for any cost ,
there exists such that .
Kernelized ridge regression
The above theorem gives us a new way of searching for : we can first search for , which might be easier, and then get back to the optimal weights by using the identity .
Therefore, for ridge regression, we can equivalently optimize our alternative formula in terms of :
We see that our data enters in kernel form. How do we get the solution to this minimization problem? We can, as always, take the gradient of the cost function according to and set it to zero:
Solving for results in:
We’ve effectively gotten back to our claimed alternative formulation for the optimal weights.
Kernel functions
The kernel is defined as . We’ll call this the linear kernel. The elements are defined as:
The kernel matrix is a matrix. Now, assume that we had first augmented the feature space with ; the elements of the kernel would then be:
Using this formulation allows us to keep the size of the same, regardless of how much we augment. In other words, we can now solve a problem where the size is independent of the feature space.
The feature augmentation goes from to with , or even to an infinite dimension.
The big advantage of using kernels is that rather than first augmenting the feature space and then computing the kernel by taking the dot product, we can do both steps together, and we can do it more efficiently.
Let’s define a kernel function . We’ll let entries in the kernel be defined by:
We can pick different kernel functions and get some interesting results. If we pick the right kernel, it can be equivalent to augmenting the features with some , and then computing the inner product:
Hopefully, is simple enough of a function that it’ll still be easier to compute than going to the higher dimensional space via and then computing the dot product.
Let’s take a look at a few examples of choices for and see what happens. In the following, we’ll go the other way around, picking a and showing that it’s equivalent to a particular feature augmentation .
Trivial kernels
This is the trivial example, in which there is no feature augmentation. The following definition of is equivalent to the identity “augmentation”:
Another trivial example assumes that . We’ll define the following kernel function, which is equivalent to the feature augmentation that takes the square:
Polynomial kernel
Let’s assume that . Let’s define the kernel function as follows:
What is the corresponding to this? The inner product that would produce the above would is produced by taking the inner product , where is defined as follows:
Radial basis function kernel
The following kernel corresponds to an infinite feature map:
This is called the radial basis function (RBF) kernel.
Consider the special case in which and are scalars; we’ll look at the Taylor expansion of the function:
We can think of this infinite sum as the dot-product of two infinite vectors, whose -th components are equal to, respectively:
Although it isn’t obvious, we’ll state that this kernel cannot be represented as an inner product in finite-dimensional space; it is inherently the product of infinite dimensional vectors.
New kernel functions from old ones
We can simply construct a new kernel as a linear combination of old kernels:
Proofs are in the lecture notes. If we accept these, we can combine them to prove much more complex kernel functions.
Classifying with the kernel
So far, we’ve seen how to compute the optimal parameter using only the kernel, without having to go to the extended feature space. This also allows us to have infinite feature spaces. Now, let’s see how to use all of this to create predictions using only the kernel.
Recall that the classifier predicts , and that . This leads us to:
Properties of kernels
How can we ensure that there exists a feature augmentation corresponding to a given kernel ? A kernel function must be an inner-product in some feature space. Mercer’s condition states that we have this iff the following conditions are fulfilled:
- is symmetric, i.e.
- For any arbitrary input set and all , is positive semi-definite
Unsupervised learning
So far, all we’ve done is supervised learning: we’ve gone from a training set with features vectors and labels, and we wanted to output a classification or a regression.
There is a second very important framework in ML called unsupervised learning. Here, the training set is only composed of the feature vectors; there are no associated labels:
We would then like to learn from this dataset without having access to the training labels. The two main directions in unsupervised learning are:
- Representation learning & feature learning
- Density estimation & generative models
Let’s take a bird’s eye view of the existing techniques through some examples.
-
Matrix factorization: can be used for both supervised and unsupervised. We’ll give an example for each
- Netflix, collaborative filtering: this is an example of supervised learning. We have a large, sparse matrix with rows of users, columns of movies, containing ratings. If we can approximate the matrix reasonably well by a matrix of rank one (i.e. outer product of two vectors), then this extracts useful features both for the users and the movies; it might group movies by genres, and users by type.
- word2vec: this is an example of unsupervised learning. The idea is to map every word from a large corpus to a vector , where K is relatively large. This would allow us to represent natural language in some numeric space. To get this, we build a matrix , with being the number of words in the corpus. We then factorize the matrix by means of two matrices of rank to give us the desired representation. The results are pretty astounding, as this article shows; closely related words are close in the vector space, and it’s easy to get a mapping from concepts to associated concepts (say, countries to capitals).
- PCA and SVD (Principle Component Analysis and Singular Value Decomposition): Features are vectors in for some d. If we wanted to “compress” this down to one dimension (this doesn’t have to be an existing feature, it could be a newly generated one from the existing ones), we could ask that the variance of the projected data be as large as possible. This will lead us to PCA, which we compute using SVD.
- Clustering: to reveal structure in data, we can cluster points given some similarity measure (e.g. Euclidean distance) and the number of clusters we want. We can also ask clusters to be hierarchical (clusters within clusters).
-
Generative models: a generative model models the distribution of the data
- Auto-encoders: these are a form of compression algorithm, trying to find good weights for encoding and compressing the data
- Generative Adversarial Networks (GANs): the idea is to use two neural nets, one that tries to generate samples that look like the data we get, and another that tries to distinguish the real samples from the fake ones. The aim is that after sufficient training, a classifier cannot distinguish real samples from artificial ones. If we achieve that, then we have built a good model.
K-Means
A common algorithm for unsupervised learning is called K-means (also called vector quantization in signal processing, or the Baum-Welch algorithm for hidden Markov models). The aim of this algorithm is to cluster the data: we want to find a partition such that every point is exactly one group, such that within a group, the (Euclidean) distance between points is much smaller than across the groups.
In K-means, we find these clusters in terms of cluster centers (also called means). Each center dictates the partition: which cluster a point belongs to depends on which center is closest to the point. In other words, we’re minimizing the distance over all points and clusters:
The is the kth number in the vector, which is a one-hot vector encoding the cluster assignment. Every datapoint has an associated vector of length K, that takes value 1 in the index of the cluster to which belongs, and 0 everywhere else. Mathematically, we can write this constraint as:
To recap, we have the following vectors:
This formulation of the problem gives rise to two conditions, which will give us an intuitive algorithm for solving this iteratively. We see that there are two sets of variables to optimize under: and . The idea is to fix one and optimize the other.
First, let’s fix the centers and work on the assignments. To minimize the sum:
Intuitively, this means that we’re grouping the points by the closest center.
Having computed this, we can fix the assignments to compute optimal centers . These centers should correspond to the center of the cluster. This minimizes the distance that all points can have to the center.
Note that in this formulation, is fixed by , and varies in the sum. This gives us some kind of average: the sum of all the positions of the points in the cluster, divided by the number of points in the cluster.
How did we get to this formulation? If we take the derivative of the cost function and set it to zero, and then solve it for , we get to the above.
Solving this confirms that taking the average position in the cluster indeed is the best way to optimize our cost.
These observations give rise to an algorithm:
- Initialize the centers . In practice, the algorithm’s convergence may depend on this choice, but there is no general best strategy. As such, they can in general be initialized randomly.
- Repeat until convergence:
- Choose given
- Choose given
Each of these two steps will only make the partitioning better, if possible. Still, this may get stuck at a local minimum, there’s no guarantee of it converging to the global optimum; it’s a greedy algorithm.
Coordinate descent interpretation
There are other ways to look at K-means. One way is to think of it as a coordinate descent, minimizing a cost function by finding parameters and iteratively:
This doesn’t actually give us much new insight, but it’s a nice way to think about it.
Matrix factorization interpretation
Another way to think about it is as a matrix factorization. We can rewrite K-means as the following minimization:
A few notes on this notation:
- is, as always, the data matrix
- is a matrix representing the mean, the vectors; each column represents a different center
- is the assignment matrix containing the vectors. This means that the columns of are one-hot vectors, i.e. that exactly one element of each column of is 1
- computes a matrix whose rows are vectors from each point to its corresponding cluster center.
- The norm here is the Frobenius norm, the sum of the squares of all elements in matrix. Using the Frobenius norm allows us to get a sum of errors squared, which should be reminiscent of most loss functions we’ve used so far
This is indeed a matrix factorization as we’re trying to find two matrices and that minimize the above criterion.
Probabilistic interpretation
A probabilistic interpretation of K-means will lead us to Gaussian Mixture Models (GMMs). Having a probabilistic approach is useful because it allows us to account for the model that we think generated the data.
The assumption is that we have generated the data by using separate -dimensional Gaussian distributions. Each sample comes from one of the distributions uniformly at random. These distributions are assumed to have means , and the identity matrix as their covariance matrix (that is, variance 1 in each dimension, and the dimensions are i.i.d).
Let’s write down the likelihood of a sample . It’s the Gaussian density function of the cluster to which the sample belongs:
The density assuming that we know that the points are from a given is what’s inside of the large parentheses. We use in the exponent to cancel out the contributions of the clusters to which does not belong, keeping only the contribution of its cluster.
Now, if we want the likelihood for the whole set instead of for a single sample, assuming that the samples are i.i.d, we can take the product over all samples:
This is the likelihood, which we want to maximize. We could equivalently minimize the log-likelihood. We’ll also remove the constant factor as it has no influence on our minimization.
And this is of course the cost function we were optimizing before.
Issues with K-means
- Computation may be heavy for large values of , and
- Clusters are forced to be spherical (and cannot be elliptical for instance)
- Each input can belong to only one cluster (this is known as “hard” cluster assignment, as opposed to “soft” assignment which allows for weighted memberships in different clusters)
Gaussian Mixture Model (GMM)
So now that we’ve expressed K-means from a probabilistic view, let’s view the probabilistic generalization, which is called a Gaussian Mixture Model.
Clustering with Gaussians
To generalize the previous, what if our data comes from Gaussian sources that aren’t perfectly circularly symmetric10, that don’t have the identity matrix as variance? A more general solution is to allow for an arbitrary covariance matrix . This will add another parameter that we need optimize over, but can help us more accurately model the data.
Soft clustering
Another extension is that we were previously forced to be either from one or another distribution. This is called hard clustering. We can generalize this to soft clustering, where a point can be associated to multiple clusters. In soft clustering, we model as a random variable taking values in , instead of a one-hot vector .
This assignment is given by a certain distribution. We denote the prior probability that the sample comes from the kth Gaussian , by :
Likelihood
What we’re trying to minimize in this extended model is then (still under the assumption that the data is independently distributed from samples):
Our notation here maybe isn’t the best; we’re still using as an indicator, but also as a random variable, and not a one-hot vector anymore. Therefore, to be clear, we should define .
This is the model that we’ll use. It’s not something that we aim to prove or not prove, it’s just what we chose to base ourselves on. We’ll want to optimize over and .
The variable is what’s known asf a latent variable; it’s not something that we observe directly, it’s just something that we use to make our model more complex. The parameters of the model are .
Marginal likelihood
The advantage of treating are latent variables instead of parameters is that we can marginalize them out to get a cost function that doesn’t depend on them. If we’re not interested in these latent variables, we can integrate over the latent variables to get the marginal likelihood:
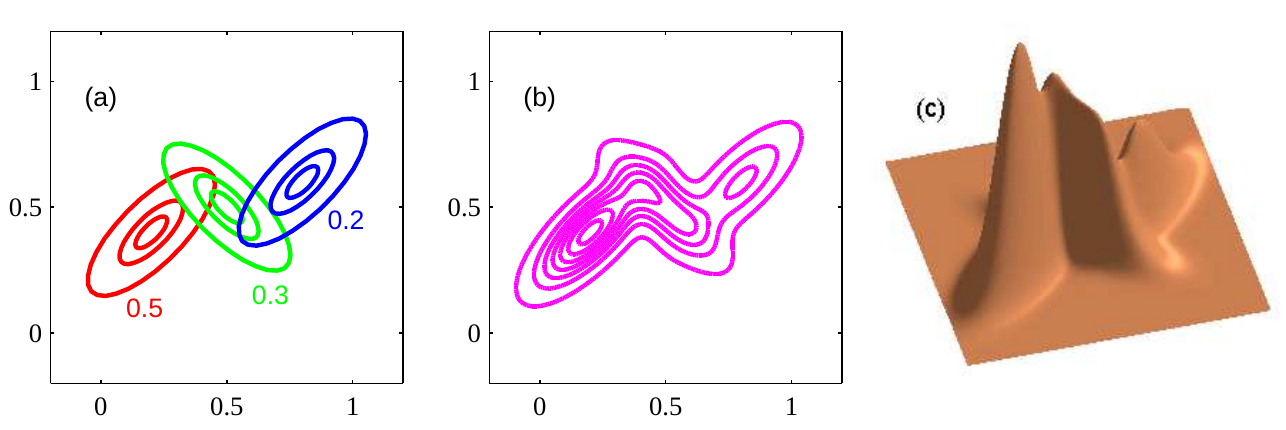
This is a weighted sum of all the models. The weights sum up to one, so we have a valid density. In other words, we are now able to model much more complex distribution functions by building up our distribution from Gaussian distributions.

Assuming that , the number of parameters in the model was , because we had an assignment for each of the datapoints. Now, assignments are no longer a parameter, so the number of parameters grows in , since we have covariance matrices, which are , and -dimensional clusters. Under our assumption that , having parameters is much better.
Maximum likelihood
We can optimize the fit of the model by changing the parameters of and optimizing the log likelihood of the above, which is:
This can be optimized over . Unfortunately, we now have the log of a sum of Gaussians (which are exponentials), which isn’t a very nice formula. We’ll use this as an excuse to talk about another algorithm, the EM algorithm.
EM algorithm
In GMM, we had the following set of parameters:
We wanted to optimize these parameters under the following maximization problem:
Note that in this problem, we’re maximizing the cost function instead of minimizing it as we’re used to. This is strictly equivalent to minimizing the negative of this, and we’re using maximizing and minimizing the negative equivalently.
This is not an easy optimization problem, because wee need to optimize the logarithm of a sum over all choices of .
The expectation-maximization (EM) algorithm provides with a general method to tackle this kind of problem. It uses an iterative two-step algorithm: at every step, we try to go from a set of parameters to a better set of parameters .
In the following, we’ll consider an arbitrary probability distribution over members. Since it is a probability distribution, we have:
The EM algorithm consists of optimizing for and alternatively. Note that while every step improves the cost, there is no guarantee that this will converge to the global optimum.
We start by initializing . Then, we iterate between the E and M steps until stabilizes.
Expectation step
In the expectation step, we compute how well we’re doing:
We can then choose the new values:
This gives us a new lower bound on the cost:
Getting a lower bound means that we have a monotonically non-decreasing cost over the steps . Again, this is a good guarantee because we’re maximizing over the cost: it tells us that our E-step improves at every step.
This value is actually the expected value, hence the name of the E-step. We’ll see this in the interpretation section below.
Derivation
Due to the concavity of the log function, we can apply Jensen’s inequality recursively to the cost function to get:
Just like in the log-sum inequality, we have equality when the terms in the log are equal for all members of the sum. If that is the case, it means that all these terms are the same scalar, and therefore that the numerator and denominator are proportional:
Since is a probability, it must sum up to 1 so we have:
Maximization step
We update the parameters as follows:
Derivation
We had previously let be an abstract, undefined distribution. We now freeze the assignments, and optimize over .
In the E step, we derived a lower bound for the cost function. In general, the lower bound is not equal to the original cost. We can however carefully choose to achieve equality. And since we want to maximize the original cost function, it makes sense to maximize this lower bound. Thus, we’ll work under this locked assignment of (thus achieving equality for the lower bound). Seeing that we have equality, our objective function (which we want to maximize) is:
This leads us to maximizing the expression:
The should sum up to one, so we’re dealing with a constrained optimization problem. We therefore add a term to turn it into an unconstrained problem. We therefore want to maximize the following over :
Differentiating with respect to , and setting the result to 0 yields:
Solving for gives us:
We can choose so that this leads to a proper normalization ( summing up to 1); this leads us to . Hence, we have:
This is our first update rule. Let’s see how to derive the others. The term has the form:
We used the fact that for an invertible matrix, . Differentiating the cost function with respect to and setting the result to 0 yields:
We can multiply this by on the left to get rid of the , and solve for to get:
Finally, for the update rule, we take the derivative with respect to and set the result to 0, yielding:
Solving for yields:
We’re using the following fact, which I won’t go into details to prove:
Interpretation
The original model for GMM was that our data points are i.i.d. from a mixture model with Gaussian components. This led us to the following choice of prior distribution:
Note that we can generalize the EM algorithm to other choices of , but that this is the one we used here.
This probability is an expectation based on the prior . Let’s now look at the posterior distribution of , given the datapoints :
The distribution that we previously just explained as an abstract, unknown distribution is in fact the posterior .
We can now explain why the E step is the expectation step. Assume that we know the (as a thought experiment, imagine a genie told us the assignment probabilities of each sample to a component , which is exactly what the quantities are).
As a reminder, the log-likelihood is:
Given the parameters , the expected value of the above log-likelihood, over the distribution of , is:
Summing this over all samples , we find the cost
This is almost the same as the expression we maximized in the derivation for the M step, modulo the terms , which are just constants for the maximization.
With this probabilistic interpretation, can write the whole EM algorithm compactly as:
Matrix Factorization
Matrix factorization is a form of unsupervised learning. A well-known example in which matrix factorization was used is the Netflix prize. The goal was to predict ratings of users for movies, given a very sparse matrix of ratings. We’ll study the method that achieved the best error.
Let’s describe the data a little more formally. Given movies and users , we define as the matrix11 containing all rating entries; that is, is the rating of the nth user for the dth movie. We don’t have any additional information on the users or on the movies, apart from the ID that’s been assigned to them. In practice, the matrix was and , and 99.98% unobserved.
We want to give a prediction for all the unobserved entries, so that we can give the top entries (say, top 10 movies) for each user.
Prediction using a matrix factorization
We will aim to find and such that:
The hope is to “explain” each rating by a numerical representation of the corresponding movie and user.
Here, we have a “tall” matrix , and , forming a “flat matrix” . In practice, compared to the size of or , will be relatively small (maybe 50 or so).
We’ll assign a cost function that we’re trying to optimize:
Here, is given. It collects the indices of the observed ratings of the input matrix . Our cost function here compares the number of stars a user assigned to a movie, to the prediction of our model , by using mean squares.
To optimize this cost function, we need to know whether it is jointly convex with respect to and , and whether it is identifiable (there is a unique minimum).
We won’t go into the full proof, but the answer is the minimum is not unique. Since is a product, we could just divide one by 10 and multiply the other by 10 to get a different solution with the same cost.
And in fact, it’s not even convex. We could compute the Hessian, which is:
This isn’t positive semi-definite, and therefore the product isn’t convex.
If we think of and as numbers (or as matrices), we can give a simpler explanation, that also gives us the intuition for why this isn’t convex. The function looks like a saddle function, and therefore isn’t convex.
Choosing K
is the number of latent features. This is comparable to the K we chose in K-means, defining the number of clusters. Large values of K facilitate overfitting.
Regularization
We can add a regularizer and minimize the following cost:
With scalars .
Stochastic gradient descent
With our cost functions in place, we can look at our standard algorithm for minimization. We’ll define loss as a sum of many individual loss functions:
Let’s derive the stochastic gradient for an individual loss function (which is what we need to compute when doing SGD). Matrix calculus is not easy, but understanding it starts with understanding the following sentence: a gradient with respect to a matrix is a matrix of gradients. If we compute the gradient of a function with respect to a matrix , we get a gradient matrix , where each element is the derivative of with respect to the element of :
Before we find the stochastic gradient, let’s start by just looking at the dimensions of what we’re going to compute:
Luckily, we’re not doing the full gradient here, but only the stochastic gradient, which only requires computing a single entry in the gradient matrix. Therefore, for a fixed pair (that is, a rating from user of movie ), we will compute a single entry in the derivative:
The same goes for the derivative by . We’ll compute a single entry in :
With these, we have the formulation for the whole matrices.
It turns out that computing this is very cheap: . This is the greatest advantage of using SGD for this. There are no guarantees that this works though; this is still an open research question. But in practice, it works really well.
The update step is then:
With stochastic gradient descent, we only compute the gradient of a single instead of the whole cost . Therefore, each step only updates the dth row of , and the nth row of .
Alternating least squares (ALS)
The alternating minimization algorithm alternates between optimizing and . ALS is a special case of this, with square error.
No missing entries
For simplicity, let’s just assume that there are no missing entries in the data matrix, that is (instead of ). This makes our life a little easier, and we’ll be able to find a closed form solution (indeed, if is the whole set, the problem is pretty easy to solve; if it’s an arbitrary subset, it becomes a NP-hard problem). Our cost is then:
ALS then does a coordinate descent to minimize the cost (plus a regularizer). First, we fix and compute the minimum with respect to (we ignore the other regularizer, as minimization is the same with or without an added constant):
Then, we alternate, minimizing and fixing :
These are two least squares problems. The only difference is that we’re searching for a whole matrix in this case, unlike in least squares where we searched for a vector. Still, we can find a closed form for it by setting the gradient with respect to and then to 0, which will give:
Note that the regularization helps us make sure that problem indeed is invertible (since we’re adding an identity matrix). This means that we can find a closed form solution if we don’t have any missing entries.
The cost of finding the solution in each step is then per column, and , which is not quite as good as the with SGD. Additionally, we need to construct and , which is . The inversion isn’t too bad: we’re only inverting a matrix, which is much nicer than dealing with or . Also note that there is no step size to tune, which makes it easier to deal with (though slower!).
Missing entries
As before, we can derive the ALS updates for the more general setting, where we only have certain ratings . The idea is to compute the gradient with respect to each group of variables, and set it to zero.
Text representation learning
Co-occurrence matrix
To attempt to get the meaning of words, we can start by constructing co-occurrence counts from a big corpus or text. This is a matrix in which is the number of contexts where word occurs together with word . A context is a window of words occurring together (it could be a document, paragraph, sentence, or a window of words).
For a vocabulary and context words , the co-occurrence matrix is a very sparse .
Motivation
We can’t plug string-encoded words directly into our learning models. Can we find a meaningful numerical representation for all of our data? We’d like to find a mapping, or embedding, for each word :
To construct a word embedding, we want to find a factorization of the co-occurrence matrix . Typically, we actually use as the element-wise log of the co-occurrence matrix, i.e. . We’ll find a factorization such that:
As before, we let collect the indices of non-zero counts in . In other words, contains indices of word pairs that have been observed in the same context.
For each pair of observed words , we’ll try to explain their co-occurrence count by a numerical representation of the two words; the dth row of is the representation of a word , and nth row of is the representation of a context word .
Bag of words
The naive approach would be to pick to be the size of the vocabulary, . We can then encode words as one-hot vectors taking value 1 at index . This works nicely, but has high dimensionality, and cannot capture the order of the words, which is why it’s called the bag of words approach.
But we can do this in smarter way. The idea is to pick a much lower , and try to group semantically similar words in this -dimensional space.
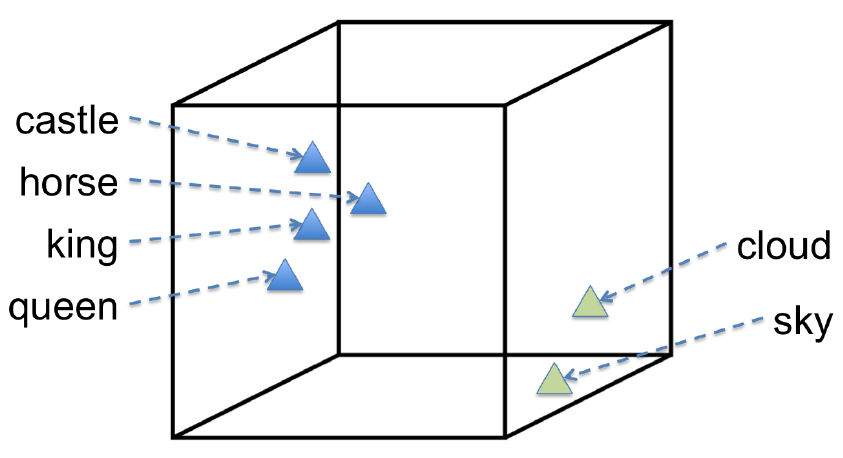
Word2vec
word2vec is an implementation of the skip-gram model. This model uses binary classification (like logistic regression) to separate real word pairs appearing together in a context window, from fake word pairs .
It does so by computing the inner product score of the words; is real, and must be distinguished from the fake .
GloVe
In the following, we’ll give an overview of the method known as GloVe (Global Vectors), which offers an alternative to word2vec.
To do this, we do the following cost minimization:
The GloVe embedding uses a little trick to weight the importance of each entry. It computes a weight used in the cost above, according to the following function:
Where is a parameter to be tuned, and is the count of and appearing together (not the log, just the normal count). This is a carefully chosen function by the GloVe creators; we can also choose if we don’t want to weigh the vectors, but GloVe achieves good results with this choice.
For , we can just choose a value, say 50, 100 or 200. Trial and error will serve us well here.
We can train the factorization with SGD or ALS.
FastText
This is another matrix factorization approach to learn document or sentence representations. Unlike the two previous approaches, FastText is a supervised algorithm.
A sentence is composed of words: . We try to optimize over the following cost function:
Where:
- and are the factorization
- is the bag-of-words representation of sentence
- is a linear classifier loss function, such as the logistic function or hinge loss
- is the classification label for sentence
SVD and PCA
Motivation
Principal Component Analysis (PCA) is a popular dimensionality reduction method. Given a data matrix, we’re looking for a way to linearly map the original dimensions into dimensions, with . The criteria for a good such mapping is that the -dimensional representation should represent the original data well.
There are different ways to think of PCA:
- It compresses data from to dimensions
- It decorrelates data, finding a -dimensional space with maximum variance
For machine learning, it’s often best not to compress data in this manner, but it may be necessary in certain situations (for reasons of interpretability for example).
In our subsequent discussion, is the data matrix, whose columns represent the feature vectors in -dimensional space.
The PCA will be computed from the data matrix using singular value decomposition.
SVD
The singular value decomposition (SVD) of a matrix is:
The matrices
- is a orthonormal12 matrix
- is a orthonormal matrix
- is a diagonal matrix (with diagonal entries)
One useful property about unitary matrices (like and , which are orthonormal, a stronger claim) is that they preserve the norms (they don’t change the length of the vectors being transformed), meaning that we can think of them as a rotation. A small proof of this follows:
We’ll assume without loss of generality (we could just take the transpose of otherwise). This is an arbitrary choice, but helps us tell the dimensions apart.
The diagonal entries in are the singular values in descending order:
The columns of and are the left and right singular vectors.
SVD and dimensionality reduction
Suppose we want to compress a data matrix to a matrix , where . We’ll define this transformation from to by the compression matrix . The decompression (or reconstruction) from to is .
Can we find good matrices? Our criteria is that the error introduced when compressing and reconstructing should be small, over all choices of compression and reconstruction matrices:
There are other ways of measuring the quality of a compression and reconstruction, but for the sake of simplicity, we’ll stick to this one.
We can actually place a bound on the reconstruction error using the following lemma.
Lemma: For any matrix and any rank-K matrix :
Where:
- is the SVD of
- are the singular values of
- is the matrix of the first rows of
If we use as our compression matrix, and as the reconstruction matrix, we get a better (or equal) error than any other choice of reconstruction . This tells us that the best compression to dimension is a projection onto the first columns of , which are the first left singular vectors.
Note that the reconstruction error is the sum of the singular values after the cut-off ; intuitively, we can think of the error as coming from the singular values we ignored.
This also tells us that the left singular vectors are ordered in decreasing order of importance. In other words, the above choice of compression uses the principal components, the most important ones. This is what really defines PCA.
The term has another simple interpretation. Let be the diagonal matrix corresponding to a truncated version of . It is of the same size, but only has the first diagonal values of , and is zero everywhere else. We claim that:
👉 It’s okay to drop the subscript on the matrix because already takes care of selecting the first rows
This tells us that the best rank approximation of a matrix is obtained by computing its SVD, and truncating it at .
SVD and matrix factorization
Expressing as an SVD allows us to easily get a matrix factorization.
This is clearly a special case of the matrix factorization as we saw it previously. In this form, the matrix factorization is perfect equality, and not an approximation—though in all fairness, this one uses . We get a less perfect (but still optimal) factorization with lower values of .
There are two differences from the general case:
- We don’t need to preselect the rank from the start. We can compute the full SVD, and control at any time later, letting it range from 1 to .
- Matrix factorization started with a with many missing entries; the idea was that the factorization should model the existing entries well, so that we can predict the missing values. This is not something that the SVD can do.
As we’ve discussed previously, this is the best rank K approximation that we can find, as the Frobenius norm of the difference between the approximation and the true value is the smallest possible (sum of the squares of the singular values).
In response to the first point above, note that we still can preselect and compute the matrix factorization that defines our dimensionality reduction:
PCA and decorrelation
Assume that we have -dimensional points in a matrix . We can compute the empirical mean and covariance by:
The covariance matrix is a rank-1 matrix. If our data is from i.i.d. samples then these empirical values will converge to the true values when .
Before we do PCA, we need to center the data around the mean. Let’s assume our data matrix has been preprocessed as such. Using the SVD, we can rewrite the empirical covariance matrix as:
This works because is an orthogonal matrix, so , and is diagonal, so , where is a diagonal matrix consisting of the D first columns of .
PCA finds orthogonal axes centered at the mean, that represent the most variance, in decreasing order of variance. Starting with orthogonal axes, it finds the rotation so that the axes point in the direction of maximum variance. This can be seen in this visual explanation of PCA.
With this intuition about PCA in mind, let’s try to decompose the covariance again, but this time considering the transformed, compressed data . The empirical covariance of along this transformed axis is:
Here, the empirical co-variance is diagonal. This means that through PCA, we’ve transformed our data to make the various components uncorrelated. This gives us some intuition of why it may be useful to first transform the data with the rotation .
Additionally, by the definition of SVD, the singular values are in decreasing order (so the first one, , is the greatest one). Since we have a diagonal matrix as our empirical variance, it means that the variance of the first component is , which proves the property of PCA’s axes being in decreasing order of variance.
Assume that we’re doing classification. Intuitively, it makes sense that classifying features with a larger variance would be easier (when the variance is 0, all data is the same and it becomes impossible to classify using that component). From this point of view, it makes intuitive sense to only keep the first rows of when we perform dimensionality reduction; we keep the features that have high variance and are uncorrelated, and we discard all features with variance close to 0 as they’re hard to classify.
Computing the SVD efficiently
To compute the SVD of a matrix , we must compute the matrices and Let’s see how we can do this efficiently.
Let’s consider the matrix . As before, since is orthogonal, we can use the SVD to get:
Let denote the jth column of .
We see that the the jth column of is the jth eigenvector of , with eigenvalue . Therefore, finding the eigenvalues and eigenvectors for gives us a way to compute and .
There’s a subtle point to be made here about the sign of the eigenvector. If is an eigenvector, then so is . But if our goal is simply to use that decomposition to do PCA, then it doesn’t matter as the sign of the columns of disappear when computing . However, if the goal is simply to do SVD, we must fix some choice of signs, and be consistent in .
To compute this decomposition, we can either work with or . This is practical, as it allows us to pick the smaller of the two and work in dimension or .
Pitfalls of PCA
Unfortunately, PCA is no miracle cure. The SVD is not invariant under scalings of the features in the original matrix . This is why it’s so important to normalize features. But there are many ways of doing this, and the result of PCA is highly dependent on how we do this, and there is a large degree of arbitrariness.
Still, the conventional approach for PCA is to remove the mean and normalize the variance to 1.
Neural Networks
Motivation
We’ve seen that simple linear classification schemes like logistic regression can work well, but also have their limitations. They work best when we add well chosen features to the original data matrix, but this can be a difficult task: a priori, we don’t know which features are useful.
We could add a ton of polynomial features and hope that some of them are useful, but this quickly becomes computationally infeasible, and leads to overfitting. To mediate the computational complexity, we can use the kernel trick; to solve the feature selection task, we could collaborate with domain experts to pick just a few good features.
But what if we could learn the features instead of having to construct them manually? This is what neural networks allow us to do.
Structure
As always in supervised learning, we start with a dataset , with .
Let’s take a look at a simple multilayer perceptron neural network. It has an input layer of size (one for each dimension of the data), hidden layers of size , and one output layer.

This is a feedforward network: the computation is performed from left to right, with no feedback loop. Each node in the hidden layer is connected to all nodes in the previous layer via a weighted edge . The number and size of hidden layers are hyperparameters to be tuned.
A node outputs a non-linear function of a weighted sum of all the nodes in the previous layer, plus a bias term. For instance, the output of node at layer is given by:
The actual learning consists of choosing all these weights appropriately for the task. The function is called the activation function. It’s very important that this is non-linear; otherwise, the whole neural net’s global function is just a linear function, which defeats the idea of having a complicated, layered function.
A typical choice for this function is the sigmoid function:
The layered structured of our neural net means that there are parameters.
How powerful are neural nets?
This chapter somewhat follows Chapter 4 of Nielsen’s book. See that for a more in-depth explanation of this argument.
We’ll state the following lemma without proof. Let , where its Fourier transform is:
We also assume that:
Essentially, these assumptions just say that our function is “sufficiently smooth” (the has to do with the smoothness; as long as it is real, the function can be shown to be continuously differentiable). Then, for all , there exists a function of the form:
This is a function that is representable by a neural net with one hidden layer with nodes and “sigmoid-like” activation functions (this is more general than just sigmoid, but includes sigmoid) such that:
This tells us that the error goes down with a rate of . Note that this only guarantees us a good approximation in a ball of radius around the center. The larger the bounded domain, the more nodes we’ll need to approximate a function to the same level (the upper bound grows in terms of ).
In fact, we’ll see that if we have enough nodes in the network, then we can approximate the underlying distribution function. There is no limit, and no real lower bounds, but we do have the property that neural nets have significant expressive power provided that they’re large enough; we’ll give an intuitive explanation of this below.
Approximation in average
We’ll give a simple and intuitive, albeit a little hand-wavy explanation as to why neural nets with sigmoid activation function and at most two hidden layers already have a large expressive power. We’re searching for an approximation “in average”, i.e. so that the integral over the absolute value of the difference is small.
In the following, we let be a scalar function on a bounded domain. This discussion generalizes to functions that are , but in these notes we’ll just cover the simple scalar function case (see Nielsen book and lecture notes for the generalization).
is Riemann integrable, meaning that it can be approximated arbitrarily precisely (with error at most , for arbitrary ) by a finite number of rectangles.
It follows that a finite number of hidden nodes can approximate any such function arbitrarily closely, since we can model rectangles with the function:
Indeed, this function takes on value at ; we can think of this as the “transition point”. The larger the value of the weight , the faster the transition from 0 to 1 happens. So if we set , the transition from 0 to 1 happens at . At this point, the derivative of if , to the width of the transition is of the order of .
All of the above says that we can create a rectangle that jumps from 0 to 1 at and jumps back to 0 at , with , with the following, taking a very large value for :
A few of these rectangles are graphed below:
This special rectangle formula has a simple representation in the form of a neural net. This network creates a rectangle from to with transition weight and height : the output of the nodes in the hidden layer is and , respectively.

Scaling this up, we can create the number of rectangles we need to do a Riemann approximation of the function.
Note that doing the Riemann integral is rarely, if ever, the best way to approximate a function. We wouldn’t want to approximate a smooth function with horrible squares. The argument here isn’t that this is an efficient approach, just that NNs are capable of doing this.
Other activation functions
The same argument also holds under other activation functions. For instance, let’s try to work it out with the rectified linear unit (ReLU) function:
Let be the function we’re trying to approximate. The Stone-Weierstrass theorem tells us that for every , there’s a polynomial locally approximating it arbitrarily precisely; that is, for all , we have:
This function can also be approximated in norm by piecewise linear function of the form:
Where is a suitable partition of . This continuity imposes the constraint:
This allows us to rewrite the function as follows:
Where:
Popular activation functions
Sigmoid
The sigmoid function has a domain of . The main problem with sigmoid is the gradient for large values of , which goes very close to zero. This is known as the “vanishing gradient problem”, which may make learning slow.
Tanh
The hyperbolic tangent has a domain of . It suffers from the same “vanishing gradient problem”.
ReLU
Rectified linear unit (ReLU) is a very popular choice, and is what works best in most cases.
ReLu is always positive, and is unbounded. A nice property about it is that its derivative is 1 (and does not vanish) for positive values of It has 0 derivative for negative values, though.
Leaky ReLU
Leaky ReLu solves the 0-derivative problem of ReLU by adding a very small slope (a hyper-parameter that can be optimized) for negative values:
Maxout
Finally, maxout is a generalization of ReLU and leaky ReLU. Again, the constants can be optimized. Note that this is quite different from previous cases, where we computed the activation function of a weighted sum. Here, we compute different weighted sums, and then choose the maximum.
SGD and Backpropagation
Remember that the value of every node is computed by:
We’d like to optimize this process. Let’s assume that we want to do a regression. Let’s denote the output of the neural net by the function . Our cost function would then simply be:
We’ll omit regularization for the simplicity of our explanation, but it can trivially be added in, without loss of generality.
To optimize our cost, we’d like to do a gradient descent. Unfortunately, this problem is not convex13, and we expect it to have many local minima, so there is no guarantee of finding an optimal solution. But the good news is that SGD is stable when applied to a neural net, which means that the outcome won’t be too dependent on the training set. SGD is still the state-of-the art in neural nets.
Let’s do a stochastic gradient descent on a single data point. We need to compute the derivative of the cost of this single point, which is:
We can gain a more general formula by restating the problem in vector form. Generally, a layer of neurons is computed by:
The overall function of the neural net is thus something taking the input layer , and passing it through all hidden layers:
To make things more convenient, we’ll introduce notation for the linear part of the computation of a layer. The computation below corresponds to our forward pass.
To be formal, we’ll just quickly state that our notation here means that we’re applying component-wise. We see that to compute a , we need ; we therefore need to start from the input layer and compute our way forward, until the last layer, which is why this is called the forward path.
Note that the full chain of computation that gets us to the output in , which is not too bad.
For the backwards pass, let’s remember that the cost of a single data-point is:
we’ll want to compute the following, which is a derivative over both and .
We can write this more compactly using , which is the Hadamard product (element-wise multiplication of vectors):
Here, to compute a , we need ; we must therefore start from the output, and compute our way back to layer 0, which is why we call this a backwards pass. Speaking of which, we will need a to start with on the the right side. Therefore, we set:
Note that , and are denoted as scalars because we assumed that our neural net only had a single output node.
Now that we have both and , let’s go back to our initial goal, which is to compute the following:
We were able re-express this as a product of these elements that we already have. We were able to drop the sum because changing a single weight only changes the single sum ; all other sums stay unchanged, and therefore do not enter into the derivative with respect to . In other words, the term is only non-zero when .
We’ve thus found the result of the two derivatives we wanted to originally find:
Regularization
To regularize the weights, we can add to the cost function. Typically, we don’t include bias terms in the regularization (experience shows that it just doesn’t work quite as well). Therefore, the regularization term is expressed as something like:
We have different weights for each layer. With the right constants , this regularization will favor small weights and can help us avoid overfitting.
Let denote the weight that we’re updating, and let be the step size. Assuming that we use the same weight for all layers , the gradient descent rule becomes:
Usual GD deducts the step size times the gradient from the variable, but here, we also decrease the weights by a factor ; we call this weight decay.
Dataset augmentation
The more data we have, the better we can train. In some instances we can generate new data from the data we are given. For instance, with the classic MNIST database of handwritten digits, we could generate new data by generating rotated characters from the existing dataset. That way, we can also train our network to become invariant to these transformations. We could also add a small amount of noise to our data (by means of compression to degree with PCA, for instance).
Dropout
We define the probability to be the probability of whether or not to keep node in layer in the network at a given step. A typical value would be , which means 80% chance of keeping a given node. This defines a different subnetwork at every step of SGD.
There are many variations of dropout; we talked about dropping nodes, but one could also drop edges. To predict, we can generate subnets and take the average prediction. Alternatively, we could use the whole network for the prediction, but scaling the output of node at layer by , which guarantees that the expected input at each node stays the same as during training.
Dropout is a method to avoid overfitting, as nodes cannot “rely” on other nodes being present. It allows us to do a kind of model averaging, as there’s an exponential number of subnetworks, and we’re averaging the training over several of them. Averaging over many models is a standard ML trick, that’s usually called bagging, which usually leads to improved performance.
Convolutional nets
The basic idea in convolutions is to slide a small window (called a filter) over an array, and computing the dot product between the filter and the elements it overlaps for every position in the array. A good introduction to the subject can be found on Eli Bendersky’s website.
Structure
Classically, we’ve defined our networks as fully connected graphs, where every node in layer is connected to every node in layer . This means that if we have nodes in each of the two layers, we have edges, and thus parameters, between them. Convolutional nets allow us to have somewhat more sparse networks.
In some scenarios, it makes sense that a more local processing of data should suffice. For instance, convolutions are commonly used in signal processing, were we have a discrete-time system (e.g. audio samples forming an audio stream), which is denoted by . To process the stream we run it through a linear filter , which produces an output . This filter is often “local”, looking at a window of size around a central value:
We have the same scenario if we think of a 2D picture, where the signal is . The filter can bring out various aspects, either smoothing features by averaging, or enhancing them by taking a so-called “high-pass” filter.
The output of the filter at position only depends on the values of the input at positions close to . This is more sparse and local than a fully connected network. This also implies that we use the same filter at every position, which drastically reduces the number of parameters.
In ML, we do something similar. We have a filter with a fixed size with coefficients for every item in the filter. We move the filter over the input matrix, and compute a weighted sum for every position in the matrix.
Padding
To handle border cases, we can either do:
- Zero padding, where give the filter a default value (usually 0) when going over the edges.
- Valid padding, where we are careful only to run the filter within the bounds of the matrix. This results in a smaller output matrix.
Channels
A picture naturally has at least three channels: every pixel has a red, green and blue component. So a 2D picture can actually be represented as a 3D cube with a depth of 3. Each layer in the depth represents the same 2D image in red, green and blue, respectively. Each such layer is called a channel.
Channels can also stem from the convolution itself. If we’re doing a convolution on a 2D picture, we may want to use multiple filters in the same model. Each of them produces a different output; these outputs are also channels. If we produce multiple 2D outputs with multiple filters, we can stack them into a 3D cube.
As we get deeper and deeper into a CNN, we tend to add more and more channels, but the 2D size of the picture typically gets smaller and smaller, either due to valid padding or subsampling. This leads to a pyramid shaped structure, as below.

Training
CNNs are different from fully connected neural nets in that only some of the edges are present, and in that they use weight sharing. The former makes our weight matrices sparser, but doesn’t require any changes in SGD or backpropagation; the latter requires a small modification in the backpropagation algorithm.
With CNNs, we run backpropagation ignoring that some weights are shared, considering each weight on each edge to be an independent variable. We then sum up the gradients of all edges that share the same weight, which gives us the gradient for the network with weight sharing.
Why we do this may seem a little counterintuitive at first, but we’ll attempt to give the mathematical intuition for it. Let’s consider a simple example, in which we let be a function from . If we let , then is no longer an independent variable, but is instead fixed to . The gradients of and are given by:
To compute the gradient of , we can first compute that of , and then realize that:
This is a general property: we can add up the derivatives of the shared weights to compute the value of a single derivative.
Bayes Nets
We’ve often seen in this course that there are multiple ways of thinking of the same things; for instance, we’ve often seen different models as variations of least squares, and seen different ways of getting back to least squares (e.g. the probabilistic approach assuming linear model with Gaussian noise, in which we maximize likelihood, or the approach in which we try to minimize MSE, etc).
But these have often been based on very simple assumptions. To model more complex models of causality, we turn to graphical models. They allow to use a graphical depiction of the relationships between random variables. The most prominent ones are Bayes Nets, Markov Random Fields and Factor Graphs.
From distribution to graphs
Assume that we’re given a large set of random variables and that we’re interested in their relationships (e.g. whether and are independent given ). It doesn’t matter if these are discrete or continuous; we’ll just think of them as being discrete, and consider to be the density.
The most generic way to write down this model is to write it as a generic distribution over a vector of random variables. The chain rule tells us:
In the above, we used the natural ordering , but we could just as well have used any of the orders: this degree of freedom will be important later. Each variable in this chain rule formulation is conditioned on other variables. For instance, for , we have:
A way to represent this expansion of the chain rule is to draw which variables are conditioned on which. In Bayes nets, we draw an arrow from each variable to the variables that are conditioned on it.

It’s important not to interpret this as causality, because the ordering that we picked chain rule is arbitrary, and could lead to many kind of arrows in the Bayes nets representation. If we just have , we could have an arrow from to just as well as the other way around. The arrows are sufficient condition to guarantee dependence, but not a necessary one: they allow for dependence, but don’t guarantee it.
Still, when we know that two variables are (conditionally) independent, we can remove edges from the graph. Perhaps we have , in which case we can draw the same graph, but without the edge from to .

This is suddenly much more interesting. Allowing to remove edges between independent variables means that we can have many different graphs. If we couldn’t do that, we would always generate the same graph with the chain rule, in the sense that it would always have the same topology; the exact ordering could still change depending on how we apply the chain rule. This is what will allow us to get information on independence from a graph.
Cyclic graphs

The above net would correspond to the factorization:
This is clearly not something that could stem from the chain rule, and therefore, the graph is not valid. In fact, we can state a stronger assertion:
Valid Bayes nets are always DAGs (directed acyclic graphs). There exists a valid distribution (a valid chain rule factorization) iff there are no cycles in the graph.
Conditional independence
Now, assume that we are given an acyclic graph. We’d like to find an appropriate ordering in the chain rule in order to find the distribution. A few things to note before we start:
- Every acyclic graph has at least one source, that is, a node that has no incoming edges
- Two random variables and are independent if
- is independent of given (which we denote by ) if
- When we talk about path in the following, we mean an undirected path
Let’s look at some simple graphs involving three variables, which will help us clarify the concept of D-separation. We’ll always ask the two same questions:
- Is ?
- Is ?
These examples have names describing whether we’re comparing the head (source) or tail (sink) of the graph when asking about (conditional) independence of and .
Tail-to-tail

is the source of this graph, so the factorization is:
Intuitively, and are not independent here, as influences them both; it would be easy to construct something where they are both correlated (e.g. if we let them be fully dictated by ).
To know if they are conditionally independent, let’s look at the conditioned quantity :
This proves .
Let’s try to look at it in more general terms. We have a path between and , which in general is worrisome as it may indicate some kind of relationship. But if we know what the value of is, then the knowledge of “blocks” that dependence.
Head-to-tail

is the source of the graph, so the factorization is:
We can clearly construct a case where and are dependent (e.g. if we pick ). So again, and are not independent.
To know if they are conditionally independent, let’s look at the conditioned quantity :
This proves . Again, conditioned on we block the path from to .
Head-to-head

Here, is the source of the graph, and the factorization is:
In this example, and are independent. But if we condition on , they become dependent. So contrary, to the two previous cases, conditioning on creates a dependence. This phenomenon is called explaining away.
D-separation
Instead of determining independence manually as we did above, we can use the two following criteria to decide on (conditional) independence graphically. We’ll give a series of nested definitions that will eventually lead to the criteria. Note that these definitions talk about sets of random variables, but this also applies to single random variables (which we can consider as a set of one).
- Let , and be sets of random variables. if and are D-separated by .
- We say that and are D-separated by iff every path from any element of to any element of is blocked by .
- We say that a path from node to node is blocked by iff it contains a variable such that either:
- is in and is head-to-tail
- is in and is tail-to-tail
- The node is head-to-head and neither this node nor any of its descendants are in
Descendant means that there exist a directed path from parent to descendant.
Examples
Let’s do lots of examples to make sure that we understand this. We’ll be working on the following graph, and ask about different combinations of random variables.

-
Is ?
First, let’s try to understand the idea of paths. There is only one path between and : from to to . In general, it doesn’t have to be a directed path, although this one happens to be so.
For every such path—and in this case, there is just one, so it’s easy—, we’ll check if it contains is a variable that is head-tail in . This is the case, and is head-to-tails with respect to this path. This means that the only path is blocked by , and therefore that .
-
Is ?
This is the same as above, except that the independence is stated in reverse. We know that independence is commutative, and it also follows from the D-separation lemma, since paths are not directed.
-
Is ?
There’s only one path from to . We’ll check if it contains a variable : the only node that fits this is quite trivially , which is head-to-tail with respect to the path. It therefore blocks the path, and we have .
-
Is ?
There’s only one path from to , and it doesn’t contain any head-to-tail or tail-to-tail nodes in . It does however contain a head-to-head node, . While has no descendants, we still have , and therefore, the lemma does not apply. The answer is therefore no.
-
Is ?
In this case, we have . There’s still only one path from to . We saw previously that we cannot apply the lemma with , so let’s try with : this node is head-to-tail with respect to the path, and belongs to . Therefore, blocks the path, and we have a D-separation, which means that the answer is yes.
-
Is ?
There’s only one path between them, which is blocked by which is head-to-head, and , and it has no descendants (so none of them are in ). Therefore, the answer is yes.
Markov blankets
Given a node , we can ask if there is a minimal set so that every random variable outside this set is conditionally independent of . The answer to this is the Markov blanket.
The Markov blanket of is the set of parents, children, and co-parents of . By co-parent, we mean other parents of the children of .

Sampling and marginalizing
So far we’ve seen how to recognize independence relationships from a Bayes net. Another possible task is to sample given a Bayes net, or to compute marginals from a Bayes net. As it turns out, these two tasks are related.
First, let’s assume we know how to sample from a Bayes net. Let’s assume that we have a set of binary random variables, . We can then generate independent samples . To get the marginal for , we estimate by computing the empirical quantity . As , we know that this converges to the true mean.
Conversely, assume we know how to efficiently compute marginals from any Bayes net, and that we’d like to sample from the joint distribution. We can then compute the marginal of the net with respect to a certain variable , and then flip a coin according to the marginal probability we’ve computed.
The problem is that neither of these can be done efficiently, except for some special cases. The chain rule tells us that is conditioned on , which means we’d need to have a table of conditional probabilities. In general, the storage requirement is exponential in the largest number of parents any node in the Bayes net has.
Factor graphs
Assume we have a function that can be factorized as follows:
A very natural representation is another graphical representation. Each variable gets a node, and each factor gets a factor node.

If the factor graph is a bipartite tree (i.e. no cycles), then we can marginalize very efficiently with a message-passing algorithm, which runs in linear time in the number of edges, instead of exponential complexity in the size of the network.
Sadly, very few probability distributions do us the favor of producing a tree in the factor graph. But it turns out that there many probability distributions where the factorization’s terms are fairly small, and despite cycles in the graph, we can still run the algorithm and it works approximately.
-
I’ve done my best to respect this notational convention everywhere in these notes, but a few mistakes may have slipped through. If you see any, please correct me in the comments below! ↩
-
To understand why, see the sections on optimality conditions and on single parameter linear regressions ↩
-
We accept this without a formal proof for now, but it should be clear from the section on convexity that MSE is convex. Otherwise, the section on normal equations for multi-parameter linear regression has more complete proofs. ↩
-
Convergence in probability means that the actual realizations of converges to that of (i.e. ), while convergence in distribution means that the distribution function of converges to that of (but without any guarantee that the actual realizations will be the same). Convergence in probability implies convergence in distribution, and is therefore a stronger assertion. ↩ ↩2
-
Fisher information is a way of measuring the information that a random variable carries about an unknown parameter. See the Wikipedia article for Fisher information. ↩
-
We say “data subset” here, because, as we’ll see later, the data available to the learning algorithm is often a subset of the whole dataset, called the training set. In this subsection, actually corresponds to . ↩
-
Because this function squeezes inputs in into a true probability in , I like the name “squishification function” that 3Blue1Brown uses, but other people also call it a “squashing” function. ↩
-
Note that this function applies the exponential function to rather large values, so we should be careful when implementing this. ↩
-
We have only studied binary logistic regression, which is the basic form of logistic regression. Generalized linear models will lead us to more complex extensions, such as multinomial logistic regression. ↩
-
The word that expresses this idea is isotropic, meaning “uniform in all directions”. ↩
-
Usually, the data matrix is , but here, we define it as the transpose, a matrix. Don’t ask me why, because I have no clue 🤷♂️ ↩
-
The columns of an orthonormal matrix are orthogonal and unitary (they have have norm 1). The transpose is equal to the inverse, meaning that if is orthogonal, then ↩
-
The cost function is no longer convex as is now a forward pass through a neural net, including multiple applications of the non-linear activation function ↩