CS-206 Parallelism and Concurrency
- Introduction
- Part 1: Parallelism
- Part 2: Concurrent programming
- Part 3: Actors
- Part 4: Big Data Analysis with Scala and Spark
These are my notes from the CS-206 Parallelism and Concurrency course. Prerequisites are:
- Functional Programming
- Algorithms
- Computer Architecture
Please note that these notes won’t be as good or complete as in the previous semester, as some of the lectures in this course were given ex cathedra instead of as a MOOC.
Introduction
Almost every desktop, laptop, mobile device today has multiple processors; it is therefore important to learn how to harness these resources. We’ll see how functional programming applies to parallelization. We’ll also learn how to estimate and measure performance.
Part 1: Parallelism
What is parallel computing?
Parallel computing is a type of computation in which many calculations are performed at the same time. The basic principle is to divide the computation into smaller subproblems, each of which can be solved simultaneously. This is, of course, assuming that parallel hardware is at our disposal, with shared access to memory. Parallel programming is much harder than sequential programming, but we can get significant speedups.
Parallelism and concurrency are closely related concepts:
- Parallel program: uses parallel hardware to execute computation more quickly. It is mainly concerned with division into subproblems and optimal use of parallel hardware
- Concurrent program: may or may not execute multiple executions at the same time. Mainly concerned with modularity, responsiveness or maintainability (convenience).
The two often overlap; neither is the superset of the other.
Parallelism manifests itself at different granularity levels.
- Bit-level parallelism: processing multiple bits of data in parallel
- Instruction-level parallelism: executing different instructions from the same instruction stream in parallel
- Task-level parallelism: executing separate instruction streams in parallel
The first two are mainly implemented in hardware or in compilers; as developers, we focus on task-level parallelism.
Parallelism on the JVM
Definitions
A process is an instance of a program that is executing in the OS. The same program can be started as a process more than once, or even simultaneously in the same OS. The operating system multiplexes many different processes and a limited number of CPUs, so that they get time slices of execution. This mechanism is called multitasking.
Two different processes cannot access each other’s memory directly — they are isolated. Interprocess communication methods exist, but they aren’t particularly straightforward.
Each process can contain multiple independent concurrency units called threads. They can be started programmatically within the program, and they share the same memory address space — this allows them to exchange information by doing memory read/writes.
Each thread has a program counter and a program stack. JVM threads can’t modify each other’s stack memory, they can only modify the heap memory.
Implementation
Each JVM process starts with a main thread. To start additional threads:
- Define a
Threadsubclass. - Instantiate a new
Threadobject. - Call
starton theThreadobject.
Notice that the same class can be used to start multiple threads.
1
2
3
4
5
6
7
8
9
10
class HelloThread extends Thread {
override def run() {
println("Hello world!")
}
}
val t = new HelloThread // new thread instance
t.start() // start thread
t.join() // wait for its completion
t.join() blocks the main thread’s execution until the t thread is done executing.
Let’s look at a more complex example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class HelloThread extends Thread {
override def run() {
println("Hello")
println("world!")
}
}
def main() {
val t = new HelloThread
val s = new HelloThread
t.start()
s.start()
t.join()
s.join()
}
Running it multiple times might yield the following output:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Hello
world!
Hello
world!
Hello
world!
Hello
world!
Hello
Hello
world!
world!
On the first two executions, the threads happened to execute linearly; first t, then s. But on the third attempt, the first thread printed Hello, but then the second thread kicked in, also printed Hello — before the first had time to print out world!, and then they both completed.
Atomicity
The above shows that two parallel threads can overlap arbitrarily. However, we sometimes want to ensure that a sequence of statements executes at once, as if they were just one statement, meaning that we don’t want them to overlap. This is called atomicity.
An operation is atomic if it appears as if it occurred instantaneously from the point of view of other threads.
The implementation of getUniqueId() below isn’t atomic, as it suffers from the same problem as the hello world example above.
1
2
3
4
5
private var uidCount = 0L // 0 as a long
def getUniqueId(): Long = {
uidCount = uidCount + 1
uidCount
}
Synchronized blocks
How can we secure it from this problem? How do we get it to execute atomically?
1
2
3
4
5
6
private val x = new AnyRef {}
private var uidCount = 0L
def getUniqueId(): Long = x.synchronized {
uidCount = uidCount + 1
uidCount
}
The synchronized block is used to achieve atomicity. Code blocks after a synchronized call on an object x are never executed on two threads at once. The JVM ensures this by storing an object called the monitor in each object. At most one thread can own the monitor at any particular time, and releases it when it’s done executing.
synchronized blocks can even be nested.
1
2
3
4
5
6
7
8
9
class Account(private var amount: Int = 0) {
def transfer(target: Account, n: Int) =
this.synchronized { // synchronized block on source account
target.synchronized { // and on target account
this.amount -= n
target.amount += n
}
}
}
This way, the thread gets a monitor on account A, and then on account B. Once it has monitors on both, it can transfer the amount from A to B. Another thread can do this with C and D in parallel.
Deadlocks
Sometimes though, this may cause the code to freeze, or to deadlock. This is a scenario in which two or more threads compete for resources (such as monitor ownership) and wait for each to finish without releasing the already acquired resources.
The following code should cause a deadlock:
1
2
3
4
5
6
7
8
val a = new Account(50)
val b = new Account(70)
// thread T1
a.transfer(b, 10)
// thread T2
b.transfer(a, 10)
T1 gets the monitor for a, T2 gets the monitor for b. Then they both wait for each other to release the monitor, leaving us in a deadlock.
Resolving deadlocks
One approach is to always acquire resources in the same order. This assumes an ordering relationship on the resources. In our example, we can simply assign unique IDs on the accounts, and order our synchronized calls according to this ID.
1
2
3
4
5
6
7
8
9
10
11
12
val uid = getUniqueUid()
private def lockAndTransfer(target: Account, n: Int) =
this.synchronized {
target.synchronized {
this.amount -= n
target.amount += n
}
}
def transfer(target: Account, n: Int) =
if (this.uid < target.uid) this.lockAndTransfer(target, n)
else target.lockAndTransfer(this, -n)
Memory model
A memory model is a set of rules describing how threads interact when accessing shared memory. Java Memory Model is the memory model for the JVM. There are many rules, but the ones we chose to remember in the context of this course are:
- Two threads writing to separate locations in memory do not need synchronization.
- A thread X that calls
joinon another thread Y is guaranteed to observe all the writes by thread Y afterjoinreturns. Note that if we don’t calljoin, there’s no guarantee that X will see any of Y’s changes when it reads in memory.
We will not be using threads and the synchronized primitive directly in the remainder of the course. However, the methods in the course are based on these, and knowledge about them is indeed useful.
Running computations in parallel
How can we run the following code in parallel?
1
2
3
4
5
6
def pNormTwoPart(a: Array[Int], p: Double): Int = {
val m = a.length / 2
val (sum1, sum2) = (sumSegment(a, p, 0, m),
sumSegment(a, p, m, a.length))
power(sum1 + sum2, 1/p)
}
We just add parallel!
1
2
3
4
5
6
def pNormTwoPart(a: Array[Int], p: Double): Int = {
val m = a.length / 2
val (sum1, sum2) = parallel(sumSegment(a, p, 0, m),
sumSegment(a, p, m, a.length))
power(sum1 + sum2, 1/p)
}
Recursion works very well with parallelism. We can for instance spin up an arbitrary number of threads:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def pNormRec(a: Array[Int], p: Double): Int =
power(segmentRec(a, p, 0, a.length), 1/p)
// like sumSegment but parallel
def segmentRec(a: Array[Int], p: Double, s: Int, t: Int) = {
if (t - s < threshold)
sumSegment(a, p, s, t) // small segment: do it sequentially
else {
val m = s + (t - s)/2
val (sum1, sum2) = parallel(segmentRec(a, p, s, m),
segmentRec(a, p, m, t))
sum1 + sum2
}
}
Signature of parallel
1
def parallel[A, B](taskA: => A, taskB: => B): (A, B) = { ... }
It returns the same value as it is given, but can do it faster than its sequential counterpart. From the point of view of the value, it is an identity function. Its arguments are taken by name (CBN); otherwise it wouldn’t be able to do much with them, as they would be evaluated sequentially before being sent to parallel. parallel needs the unevaluated computations to function, thus CBN.
Underlying hardware architecture affects performance
Sometimes, we do not achieve any speedup even though we ran computations in parallel. For instance, if we sum up array elements instead of summing powers of array elements like above, we don’t see any speedups using parallelism. This is because this computation is bound by the memory bandwidth, which acts as a bottleneck to any speedup.
Therefore, when considering opportunities for speed-up, we must take into account not only the number of cores, but also the parallelism available for any other shared resources that we might need in order to perform computation, such as memory in this case.
In general, parallel computation takes as long as its slowest / longest thread.
Tasks
Instead of invoking threads, we can use a more flexible construct for parallel computation: tasks.
1
2
3
4
val t1 = task(e1)
val t2 = task(e2)
val v1 = t1.join
val v2 = t2.join
t = task(e) starts a computation “in the background”; the main thread continues while the task is running (unless we use join in which case it waits). Tasks are easier to use; instead of this mess with nested calls to parallel:
1
2
3
4
5
6
val ((part1, part2),(part3,part4)) =
parallel(parallel(sumSegment(a, p, 0, mid1),
sumSegment(a, p, mid1, mid2)),
parallel(sumSegment(a, p, mid2, mid3),
sumSegment(a, p, mid3, a.length)))
power(part1 + part2 + part3 + part4, 1/p)
We can easily get 4 tasks by doing:
1
2
3
4
5
val t1 = task {sumSegment(a, p, 0, mid1)}
val t2 = task {sumSegment(a, p, mid1, mid2)}
val t3 = task {sumSegment(a, p, mid2, mid3)}
val t4 = task {sumSegment(a, p, mid3, a.length)}
power(t1 + t2 + t3 + t4, 1/p)
We don’t call join, it’s implicit?
How do we measure performance?
Work and depth
We introduce two measures for a program:
-
Work
W(e): number of stepsewould take if there was no parallelism. This is simply the sequential execution time -
Depth
D(e): number of steps if we had unbounded parallelism
The key rules are:
- .
- .
For parts of code where we do not use parallel explicitly, we must add up
costs. For function call or operation :
- .
- .
Here denotes values of . If is a primitive operation on integers, then and are constant functions, regardless of .
Suppose we know and and our platform has P parallel threads. It is reasonable to use this estimate for running time:
Given and , we can estimate how programs behave for different :
- If is constant but inputs grow, parallel programs have the same asymptotic time complexity as sequential ones.
- Even with infinite resources () we have non-zero complexity given by .
Asymptotic analysis
Asymptotic analysis allows us to understand how the runtime of our algorithm changes when the inputs get larger or when we have more parallel hardware available. Just like in Algorithms, we consider the worst case to get an upper bound using big-O notation.
Let’s look at an example:
1
2
3
4
5
6
7
8
9
def sumSegment(a: Array[Int], p: Double, s: Int, t: Int): Int = {
var i = s
var sum: Int = 0
while (i < t) {
sum += power(a(i), p)
i += 1
}
sum
}
The running time is linear in the time between t and s, , a function of the form .
Now what about this recursive function?
1
2
3
4
5
6
7
8
9
10
def segmentRec(a: Array[Int], p: Double, s: Int, t: Int) = {
if (t - s < threshold)
sumSegment(a, p, s, t)
else {
val m = s + (t - s)/2
val (sum1, sum2) = (segmentRec(a, p, s, m),
segmentRec(a, p, m, t))
sum1 + sum2
}
}
The cost (work) of this function is:
is some function overhead, the cost of calculating the middle m and starting two parallel threads. Assume , where is the depth of the tree (how we “split our program into two”). The computation tree has leaves and internal nodes, so:
For each internal node, we do work, and for each leaf we do work. If we look at what is constant, we can write it in the above form. If we pick our so that (meaning we just find the closest power of 2 approximation), we have:
in , so our function is in . What if we now make it parallel?
1
2
3
4
5
6
7
8
9
10
11
12
def segmentRec(a: Array[Int], p: Double, s: Int, t: Int) = {
if (t - s < threshold)
sumSegment(a, p, s, t)
else {
val m = s + (t - s)/2
val (sum1, sum2) = parallel(
segmentRec(a, p, s, m),
segmentRec(a, p, m, t)
)
sum1 + sum2
}
}
The depth of our computation tree is given by:
Since we’re running the branches of the computation tree in parallel, the depth will be the max of the left and the right branch, plus some constant overhead. Let’s assume again that is of the convenient form , where is the depth of the tree. The computation tree has leaves and internal nodes.
- Leaves of computation tree:
- One level above:
- Two levels above:
- …
- Root:
Since is the depth of the tree. Our depth is thus bounded by . As before, running time is monotonic is . Let’s pick our to approximate our depth, meaning that for , we have . This is an important result, since combined with the idea that depth is bounded by , we conclude that is . This means that parallelization has taken us from linear to logarithmic runtime (assuming unlimited parallelization).
Empirical analysis: Benchmarking
Measuring performance is difficult. To ensure somewhat reliable results, we need a strict measurement methodology involving:
- Multiple repetitions
- Statistical treatment – computing mean and variance
- Eliminating outliers
- Ensuring steady state (warm-up)
- Preventing anomalies (GC, JIT compilation, aggressive optimizations)
This is all quite complex, so we use a tool to do it for us: ScalaMeter. To use it, we first need to add it as a dependency in build.sbt:
1
2
libraryDependencies +=
"com.storm-enroute" %% "scalameter-core" % "0.6"
Then we can use it as such:
1
2
3
4
5
6
7
import org.scalameter._
val time = measure {
(0 until 1000000).toArray
}
println(s"Array initialization time: $time ms")
But this yields unreliable results due to garbage collection and dynamic optimization and stuff like that. Running it multiple times can yield anything from 7 to 50ms. We notice that the program runs in about 7ms after a few runs; this is the JVM Warmup.
ScalaMeter can ensure that warm-up has taken place if we do:
1
2
3
4
5
import org.scalameter._
val time = withWarmer(new Warmer.Default) measure {
(0 until 1000000).toArray
}
If we are not entirely satisfied with the defaults settings of ScalaMeter, we can change them as such:
1
2
3
4
5
6
7
val time = config(
Key.exec.minWarmupRuns -> 20,
Key.exec.maxWarmupRuns -> 60,
Key.verbose -> true // increase verbosity
) withWarmer(new Warmer.Default) measure {
(0 until 1000000).toArray
}
Finally, ScalaMeter can measure more than just the running time:
-
Measurer.Default: plain running time -
IgnoringGC: running time without GC pauses -
OutlierElimination: removes statistical outliers -
MemoryFootprint: memory footprint of an object -
GarbageCollectionCycles: total number of GC pauses
Parallelizing important algorithms
Parallel merge sort
As we mentioned in Algorithms, Merge Sort works very well in parallel. We’ll see how to do just that now. We’ll use two arrays xs and ys, where ys is just a temporary array to which we’ll be copying elements from the original array xs.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def sort(from: Int, until: Int, depth: Int): Unit = {
if (depth == maxDepth) { // base case
quickSort(xs, from, until - from)
} else { // recursively parallelize
// Divide
val mid = (from + until) / 2
parallel(sort(mid, until, depth + 1), sort(from, mid, depth + 1))
// Merge two sorted sublists
val flip = (maxDepth - depth) % 2 == 0
val src = if (flip) ys else xs
val dst = if (flip) xs else ys
merge(src, dst, from, mid, until)
}
}
def merge(src: Array[Int], dst: Array[Int],
from: Int, mid: Int, until: Int): Unit
sort(0, xs.length, 0)
The merge implementation is sequential, so we will not go through it. Benchmarking this parallel merge sort to the Scala quicksort implementation shows up to a two-fold speedup in practice.
Copying array in parallel
To copy the temporary array into the original one, we need an optimized algorithm:
1
2
3
4
5
6
7
8
9
10
11
12
13
def copy(src: Array[Int], target: Array[Int],
from: Int, until: Int, depth: Int): Unit = {
if (depth == maxDepth) {
Array.copy(src, from, target, from, until - from)
} else {
val mid = (from + until) / 2
val right = parallel(
copy(src, target, mid, until, depth + 1),
copy(src, target, from, mid, depth + 1)
)
}
}
if (maxDepth % 2 == 0) copy(ys, xs, 0, xs.length, 0)
Parallel map
Some operations we saw in the previous course were map, fold and scan (like fold but stores intermediate results).
Lists aren’t terribly efficient, as splitting them in half and combining them take linear time. As alternatives, we’ll use arrays and trees in our implementation. We’ll see more about Scala’s parallel collection libraries in future lectures.
1
2
3
4
5
6
7
8
9
10
11
def mapASegPar[A,B](inp: Array[A], left: Int, right: Int, f : A => B,
out: Array[B]): Unit = {
// Writes to out(i) for left <= i <= right-1
if (right - left < threshold)
mapASegSeq(inp, left, right, f, out) // assuming a sequential implementation has been defined as such
else {
val mid = left + (right - left)/2
parallel(mapASegPar(inp, left, mid, f, out),
mapASegPar(inp, mid, right, f, out))
}
}
Parallelization yields 5x or 6x speedup in certain benchmarks. From the benchmarks we can also tell that the parallelized map is basically as efficient as specialized implementations of operations in parallel.
If we use trees instead of arrays:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def mapTreePar[A:Manifest,B:Manifest](t: Tree[A], f: A => B) : Tree[B] =
t match {
case Leaf(a) => { // base case
val len = a.length
val b = new Array[B](len)
var i= 0
while (i < len) {
b(i)= f(a(i))
i= i + 1
}
Leaf(b)
}
case Node(l,r) => { // recursive parallelization
val (lb,rb) = parallel(mapTreePar(l,f), mapTreePar(r,f))
Node(lb, rb) // combine computations into new node
}
}
Comparison of arrays and immutable trees
Arrays:
- (+) random access to elements, on shared memory can share array
- (+) good memory locality
- (-) imperative: must ensure parallel tasks write to disjoint parts
- (-) expensive to concatenate
Immutable trees:
- (+) purely functional, produce new trees, keep old ones
- (+) no need to worry about disjointness of writes by parallel tasks
- (+) efficient to combine two trees
- (-) high memory allocation overhead
- (-) bad locality
Parallel reduce
For reduce (or fold), the order of operation matters. When we process the elements in parallel, we must therefore impose that the operation be associative, meaning that the order doesn’t matter. Examples of associative operations include addition or concatenation of strings, but not subtraction.
An operation f: (A, A) => A is associative if and only if for every x, y, z, f(x, f(y, z)) == f(f(x, y), z).
We can represent the reduction as an operation tree, where every node corresponds to a single operation (say, addition or concatenation). If t1 and t2 are different tree representations of the same reduction (so they correspond to the same reduction, but in a different order), and f: (A, A) => A is associative, then:
1
reduce(t1, f) == reduce(t2, f)
If we want to implement reduce for arrays instead of trees, we can just conceptually consider arrays as trees by cutting them in half at every step (until a certain threshold size):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def reduceSeg[A](inp: Array[A], left: Int, right: Int, f: (A,A) => A): A = {
if (right - left < threshold) {
var res= inp(left); var i= left+1
while (i < right) {
res= f(res, inp(i))
i= i+1
}
res
} else {
val mid = left + (right - left)/2
val (a1,a2) = parallel(reduceSeg(inp, left, mid, f),
reduceSeg(inp, mid, right, f))
f(a1,a2)
}
}
def reduce[A](inp: Array[A], f: (A,A) => A): A =
reduceSeg(inp, 0, inp.length, f)
Associative and/or commutative operations
Associative and commutative operations:
- Addition and multiplication of mathematical integers (
BigInt) and of exact rational numbers (given as, e.g., pairs ofBigInts) - Addition and multiplication modulo a positive integer (e.g. 232),
including the usual arithmetic on 32-bit
Intor 64-bitLongvalues - Union, intersection, and symmetric difference of sets
- Union of bags (multisets) that preserves duplicate elements
- Boolean operations
&&,||,xor - Addition and multiplication of polynomials
- Addition of vectors
- Addition of matrices of fixed dimension
Associative but not commutative operations:
- Concatenation (append) of lists:
(x ++ y) ++ z == x ++ (y ++ z) - Concatenation of
Strings(which can be viewed as lists ofChar) - Matrix multiplication AB for matrices A and B of compatible dimensions
- Composition of relations
- Composition of functions
Many operations Commutative but not associative, such as . Interestingly, addition or multiplication of floating point numbers is commutative, but not associative. This is because of floating point errors (where they’re off by 0.000...01), so we don’t always have
1
(x + mx) + e == x + (mx + e)
As a conclusion, proving commutativity alone does not prove associativity. Another thing to look out for is that associativity is not preserved by mapping; when combining and optimizing reduce and map invocations, we need to be careful that operations given to reduce remain associative.
Making an operation commutative is easy
Suppose we have a binary operation g and a strict total ordering less (e.g. lexicographical ordering of bit representations). Then this operation is commutative:
1
def f(x: A, y: A) = if (less(y,x)) g(y,x) else g(x,y)
There is no such trick for associativity, though.
Constructing associative operations
Suppose f1: (A1,A1) => A1 and f2: (A2,A2) => A2 are associative.
Then f: ((A1,A2), (A1,A2)) => (A1,A2) defined by
1
f((x1,x2), (y1,y2)) = (f1(x1,y1), f2(x2,y2))
is also associative.
The following functions are also associative:
1
2
3
4
5
6
7
8
9
10
times((x1,y1), (x2, y2)) = (x1*x2, y1*y2)
// Calculating average
val sum = reduce(collection, _ + _)
val length = reduce(map(collection, (x:Int) => 1), _ + _)
sum/length
// Equivalently
val (sum, length) = reduce(map(collection, (x:Int) => (x,1)), f)
sum/length
There are some situations where commutativity can help us establish associativity, but we need some additional property. Let:
1
E(x,y,z) = f(f(x,y), z)
We say arguments of E can rotate if:
1
2
3
E(x,y,z) = E(y,z,x)
// equivalent to
f(f(x,y), z) = f(f(y,z), x)
If the above function f is commutative and the arguments if E can rotate, then f is also associative. Proof:
1
f(f(x,y), z) = f(f(y,z), x) = f(x, f(y,z))
We can use this to prove associativity for the following examples:
1
plus((x1,y1), (x2, y2)) = (x1*y2 + x2*y1, y1*y2)
Again, we should be wary of floating point numbers in proving associativity!
Parallel scan
Sequentially, scanLeft can be implemented as:
1
2
3
4
5
6
7
8
9
10
11
def scanLeft[A](inp: Array[A], a0: A,
f: (A,A) => A, out: Array[A]): Unit = {
out(0) = a0
var a = a0
var i = 0
while (i < inp.length) {
a = f(a,inp(i))
i = i + 1
out(i) = a
}
}
Can this be made parallel? We’ll assume f is associative. Our goal is to have an algorithm (given infinite parallelism).
At first, this task seems almost impossible, because the value of the last element in sequence is computed from the previous element. And for every element, it looks like the natural way is indeed what we gave in the sequential algorithm. But even if we parallelize the individual applications of f, we would not be able to parallelize the traversal of the array itself. So this would give us still a linear algorithm even with infinite parallelism.
So, we need to perform computation in a different order, the idea is to give up reusing all intermediate results. And in fact, we will do more work and more applications of f that need the simple sequential version. However, this will allow us to improve parallelism and in terms of the parallel running time, more than compensate for the fact that we are applying f a few more times than in the sequential algorithm.
To show that this is even possible in parallel, here’s how we’d define it in terms of the parallel map and reduce:
1
2
3
4
5
6
def scanLeft[A](inp: Array[A], a0: A, f: (A,A) => A, out: Array[A]) = {
val fi = { (i:Int,v:A) => reduceSeg1(inp, 0, i, a0, f) }
mapSeg(inp, 0, inp.length, fi, out)
val last = inp.length - 1
out(last + 1) = f(out(last), inp(last))
}
On trees
Let’s implement scanLeft on trees.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
def upsweep[A](t: Tree[A], f: (A,A) => A): TreeRes[A] = t match {
case Leaf(v) => LeafRes(v)
case Node(l, r) => {
val (tL, tR) = parallel(upsweep(l, f), upsweep(r, f))
NodeRes(tL, f(tL.res, tR.res), tR)
}
}
// ’a0’ is reduce of all elements left of the tree ’t’
def downsweep[A](t: TreeRes[A], a0: A, f : (A,A) => A): Tree[A] = t match {
case LeafRes(a) => Leaf(f(a0, a))
case NodeRes(l, _, r) => {
val (tL, tR) = parallel(downsweep[A](l, a0, f),
downsweep[A](r, f(a0, l.res), f))
Node(tL, tR)
}
}
def prepend[A](x: A, t: Tree[A]): Tree[A] = t match {
case Leaf(v) => Node(Leaf(x), Leaf(v))
case Node(l, r) => Node(prepend(x, l), r)
}
def scanLeft[A](t: Tree[A], a0: A, f: (A,A) => A): Tree[A] = {
val tRes = upsweep(t, f)
val scan1 = downsweep(tRes, a0, f)
prepend(a0, scan1)
}
Here’s how downsweep works:

On arrays
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
def upsweep[A](inp: Array[A], from: Int, to: Int,
f: (A,A) => A): TreeResA[A] = {
if (to - from < threshold)
Leaf(from, to, reduceSeg1(inp, from + 1, to, inp(from), f))
else {
val mid = from + (to - from)/2
val (tL,tR) = parallel(upsweep(inp, from, mid, f),
upsweep(inp, mid, to, f))
Node(tL, f(tL.res,tR.res), tR)
}
}
def reduceSeg1[A](inp: Array[A], left: Int, right: Int,
a0: A, f: (A,A) => A): A = {
var a = a0
var i = left
while (i < right) {
a = f(a, inp(i))
i = i+1
}
a
}
def downsweep[A](inp: Array[A], a0: A, f: (A,A) => A,
t: TreeResA[A], out: Array[A]): Unit = t match {
case Leaf(from, to, res) =>
scanLeftSeg(inp, from, to, a0, f, out)
case Node(l, _, r) => {
val (_,_) = parallel(
downsweep(inp, a0, f, l, out),
downsweep(inp, f(a0,l.res), f, r, out))
}
}
def scanLeftSeg[A](inp: Array[A], left: Int, right: Int,
a0: A, f: (A,A) => A, out: Array[A]) = {
if (left < right) {
var i = left
var a = a0
while (i < right) {
a = f(a, inp(i))
i = i+1
out(i) = a
}
}
}
def scanLeft[A](inp: Array[A], a0: A, f: (A,A) => A,
out: Array[A]) = {
val t = upsweep(inp, 0, inp.length, f)
downsweegp(inp, a0, f, t, out) // fills out[1..inp.length]
out(0) = a0 // prepends a0
}
Data parallelism
So far, we’ve learned about task-parallel programming:
A form of parallelization that distributes execution processes across computing nodes.
In Scala, we express this with task and parallel.
Data-parallel programs have a different approach:
A form of parallelization that distributes data across computing nodes.
Why would we want to use data-parallelism? It can be much faster than task parallelism (in the demo with Mandelbrot sets, it was 2x faster).
Workload
Why are data parallel programs sometimes faster than task parallel ones?
Different data-parallel programs have different workloads. Workload is a function that maps each input element to the amount of work required to process it.
initializeArray had a workload defined by a constant function, . We call this uniform workload, and it’s really easy to parallelize.
An irregular workload is one where the work is described by an arbitrary function: . This is where we have a data-parallel scheduler, whose role is to efficiently balance the workload across processors without any knowledge about the . The idea of the scheduler is to shift away the task of balancing the workload from the programmer. They have similar semantics, so we won’t study them in detail.
Parallel for-loop
To initialize arrays with a given value in parallel (writing v to every position in xs)
1
2
3
4
5
def initializeArray(xs: Array[Int])(v: Int): Unit = {
for (i <- (0 until xs.length).par) {
xs(i) = v
}
}
Here, the .par method converts the range to a parallel range; the for loop will be executed in parallel. Parallel for-loops are not functional, do not return a value, and can therefore only communicate with the rest of the program through some side effect, such as writing to an array. Therefore, the parallel for-loop must write to separate memory locations or be synchronized in order to work.
Non-parallelizable operations
In general terms, most sequential collections can be converted to parallel collections by using .par; some collection operations subsequently applied become data-parallel, but not all. Let’s look at an example:
1
2
3
def sum(xs: Array[Int]): Int = {
xs.par.foldLeft(0)(_ + _)
}
This does not execute in parallel, as foldLeft has no way of not processing elements sequentially (its name implies that it must go left to right); foldRight, reduceLeft, reduceRight, scanLeft and scanRight similarly must process the elements sequentially and operate sequentially on parallel collections.
Parallelizable operations
However, fold (without any direction) can process elements in parallel (see LEGO bricks explanation in lecture videos). Our previous sum function, and max could be written like this instead:
1
2
3
4
5
6
7
def sum(xs: Array[Int]): Int = {
xs.par.fold(0)(_ + _)
}
def max(xs: Array[Int]): Int = {
xs.par.fold(Int.MinValue)(math.max)
}
It is important to note that fold will work with a function f if:
-
fis an associative operation - When applied to the neutral element
z, it must act as an identity function.
In other words, the following relations must hold:
1
2
f(a, f(b, c)) == f(f(a, b), c)
f(z, a) == f(a, z) == a
In more formal terms, the neutral element z and the binary operator f must form a monoid. Commutativity is not important for fold, but it is important that the neutral element z be of the same type as the collection items (unlike foldLeft); this is clear if we look at the signature of fold:
1
def fold(z: A)(f: (A, A) => A): A
This seems like a lot of limitations, so we’ll need a more powerful data parallel operation. Enter aggregate:
1
def aggregate[B](z: B)(f: (B, A) => B, g: (B, B) => B): B
What it does is divide the collection into pieces, applying the sequential folding operator f and combine results using the parallel folding operator g. Using it, we can do what we couldn’t do with fold: count the number of vowels in a character array:
1
2
3
4
Array('E', 'P', 'F', 'L').par.aggregate(0)(
(count, c) => if (isVowel(c)) count + 1 else count,
_ + _
)
Again, the parallel reduction operator g and the neutral element z should form a monoid (z should be the neutral element of g). Note that this is just an “if”, not “if and only if”; the iff condition for aggregate to work is:
1
(x1 ++ x2).foldLeft(z)(f) == g(x1.foldLeft(z)(f), x2.foldLeft(z)(f))
Alternatively, we can formulate this same requirement as two requirements, for all u and v:
1
2
g(u, z) == u // g-right-unit
g(u, f(v, x)) == f(g(u, v), x) // g-f-assoc
Many other parallel collection operations can be expressed in terms of aggregate. So far we’ve only seen accessor combinators (sum, max, fold, count, aggregate, …). Transformer combinators (such as map, filter, flatMap, groupBy) do not return a single value, but instead return new collections as a result.
Parallel collections
In sequential collections, the hierarchy is as follows:
-
Traversable[T]: collection of elements with typeT, with operations implemented using foreach-
Iterable[T]: collection of elements with typeT, with operations implemented using iterator-
Seq[T]: an ordered sequence of elements with typeT -
Set[T]: a set of elements with typeT(no duplicates) -
Map[K, V]: a map of keys with type K associated with values of type V (no duplicate keys)
-
-
Traits ParIterable[T], ParSeq[T], ParSet[T] and ParMap[K, V] are the
parallel counterparts of different sequential traits. For code that is agnostic about parallelism, there exists a separate hierarchy of generic collection traits GenIterable[T], GenSeq[T], GenSet[T] and GenMap[K, V].
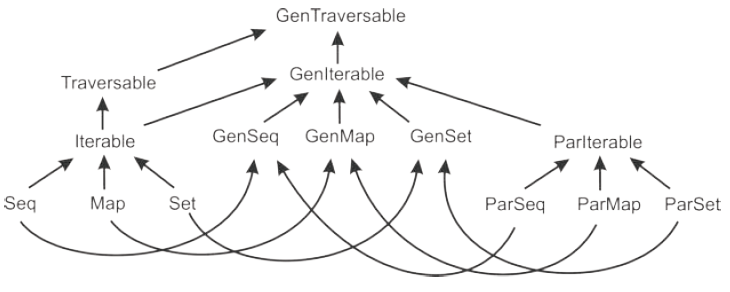
Using these generic collections, operations may or may not execute in parallel:
1
2
3
4
5
6
7
8
9
10
def largestPalindrome(xs: GenSeq[Int]): Int = {
xs.aggregate(Int.MinValue)((largest, n) =>
if (n > largest && n.toString == n.toString.reverse) n else largest,
math.max
)
}
val array = (0 until 1000000).toArray
largestPalindrome(array) // sequential
largestPalindrome(array.par) // parallel
In practice, parallelizable collections are:
-
ParArray[T]: parallel array of objects, counterpart of Array and ArrayBuffer -
ParRange: parallel range of integers, counterpart of Range -
ParVector[T]: parallel vector, counterpart of Vector -
immutable.ParHashSet[T]: counterpart of immutable.HashSet -
immutable.ParHashMap[K, V]: counterpart of immutable.HashMap -
mutable.ParHashSet[T]: counterpart of mutable.HashSet -
mutable.PasHashMap[K, V]: counterpart of mutable.HashMap -
ParTrieMap[K, V]: thread-safe parallel map with atomic snapshots, counterpart ofTrieMap - for other collections, par creates the closest parallel collection: e.g. a List is converted to a ParVector
The last point stresses the importance of picking data structures carefully and making sure that they are parallelizable; otherwise, the conversion might take longer than the parallel instructions themselves.
Avoiding parallel errors
As we’ve said previously, one should either synchronize or write to separate memory locations. To synchronize, we can use the Java ConcurrentSkipListSet[T] instead of Scala mutable Set. To avoid side-effects, we can use the right combinators (for instead, use filter instead of making your own code).
A rule to avoid concurrent modifications during traversals is to never read or write to a parallel collection on which a data-parallel operation is in progress.
The TrieMap collection is an exception to this; it atomically takes snapshots whenever a parallel operation starts, so concurrent updates aren’t observed during that time. It offers the snapshot method (efficient: constant time), which can be used to efficiently grab the current state.
Data-parallel abstractions
Transformer operations are collection operations that create another collection instead of a single value. Methods such as filter, map, flatMap, groupBy are examples of transformer operations.
Iterators
1
2
3
4
5
trait Iterator[A] {
def next(): A
def hasNext: Boolean
}
def iterator: Iterator[A] // on every collection
The iterator contract states that:
-
nextcan be called only ifhasNextreturnstrue. That means that when definingnext, one should always callhasNext. - After
hasNextreturnsfalse, it will always returnfalse
Splitters
1
2
3
4
5
trait Splitter[A] extends Iterator[A] {
def split: Seq[Splitter[A]]
def remaining: Int
}
def splitter: Splitter[A] // on every parallel collection
The splitter contract states that:
- After calling
split, the original splitter is left in an undefined state - The resulting splitters traverse disjoint subsets of the original splitter
-
remainingis an estimate on the number of remaining elements -
splitis an efficient method – or better (since we invoke it in parallel in hopes of obtaining a speedup)
Builders
Builders are abstractions for creating new sequential collections. T denotes the type of the elements of the collection (e.g. String), and Repr is the type of the resulting collection of elements (e.g. Seq[String]).
1
2
3
4
5
6
trait Builder[A, Repr] {
def +=(elem: A): Builder[A, Repr] // add element to the builder
def result: Repr // obtain collection after all elements are added
}
def newBuilder: Builder[A, Repr] // on every collection
The builder contract states that:
- Calling
resultreturns a collection of typeRepr, containing the elements that were previously added with+= - Calling
resultleaves the Builder in an undefined state (after this we cannot use it anymore)
Combiners
A combiner is a parallel version of a builder. It has the same += and result methods as it extends Builder, but adds a method combine to merge two combiners (invalidating the two old combiners in the process).
1
2
3
4
5
trait Combiner[A, Repr] extends Builder[A, Repr] {
def combine(that: Combiner[A, Repr]): Combiner[A, Repr]
}
def newCombiner: Combiner[T, Repr] // on every parallel collection
The combiner contract states that:
- Calling
combinereturns a new combiner that contains elements of input combiners - Calling
combineleaves both originalCombinersin an undefined state -
combineis an efficient method – or better (usually, this means that we should run it in parallel)
Implementing combiners
How do we implement it efficiently ()? We’ll see that this depends on the underlying data structure; Repr could be a map, a set or a sequence, and that changes everything:
- When
Repris a set or a map,combinerepresents union - When
Repris a sequence,combinerepresents concatenation
For arrays, there is no efficient combine operation. This has to do with how arrays are stored in memory; the two subarrays may be stored in different locations, which implies having to move one to the end of another; this cannot be done in logarithmic time, only in linear time.
For sets, we can use different data structures, that may have different runtimes for lookup, insertion and deletion:
- Hash tables: expected
- Balanced trees:
- Linked lists:
Unfortunately, most set implementations do not have an efficient union operation, so combine is tricky to implement.
For sequences, there are also a few data structures, with which the operation complexity varies.
- Mutable linked lists: prepend and append, insertion
- Functional (cons) lists: prepend, everything else
- Array lists: amortized append, random access, otherwise
(Amortized means that we may need to copy the array to another location when we need more space, but overall we expect it to be constant time on average.)
Mutable linked lists can have concatenation, but for most sequences, concatenation is .
All of the above shows that providing a combiner for the corresponding collections is not straightforward, since most parallel data structures do not have the efficient union or concatenation operation we want — but it is still possible to implement.
Two-phase construction
Most data structures can be constructed in parallel using two-phase construction. Here, the combiner doesn’t use the final data structure in its internal representation; it uses an intermediate data structure that:
- Has an efficient
combinemethod: or better - Has an efficient
+=method (this ensures that individual processors can efficiently modify the data structure) - Can be converted to the resulting data structure in time (n size of data structure, P number of processors)
Let’s implement it for arrays:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
class ArrayCombiner[T <: AnyRef: ClassTag](val parallelism: Int) {
// parallelism = parallelism level
private var numElems = 0 // # of elements in the combiner
private val buffers = new ArrayBuffer[ArrayBuffer[T]] // nested ArrayBuffer
buffers += new ArrayBuffer[T]
def +=(x: T) = { // Amortized O(1)
// if the ArrayBuffer ever gets full,
// it is expanded to accommodate more elements
buffers.last += x
numElems += 1
this
}
def combine(that: ArrayCombiner[T]) = { // O(P) since there are P array combiners
buffers ++= that.buffers // copies references
numElems += that.numElems
this
}
def result: Array[T] = {
val array = new Array[T](numElems)
val step = math.max(1, numElems / parallelism)
val starts = (0 until numElems by step) :+ numElems
val chunks = starts.zip(starts.tail)
val tasks = for ((from, end) <- chunks) yield task {
copyTo(array, from, end)
}
tasks.foreach(_.join())
array
}
}
Benchmarks show over 2x speedups with 4 (not linear because of the memory access bottleneck). So for arrays:
- partition the indices into subintervals
- initialize the array in parallel
For hash tables:
- partition the hash codes into buckets (e.g. linked lists of arrays) according to their hashcode prefix
- allocate the table, and map hash codes from different buckets into different regions
For search trees:
- partition the elements into non-overlapping intervals according to their ordering
- construct search trees in parallel, and link non-overlapping trees (which is efficient when they’re non-overlapping)
Spatial data structures (see exercises):
- spatially partition the elements
- construct non-overlapping subsets and link them
So as a conclusion, how can we implement combiners?
- Two-phase construction: the combiner uses an intermediate data structure with an efficient combine method to partition the elements. When result is called, the final data structure is constructed in parallel from the intermediate data structure.
- An efficient concatenation or union operation: a preferred way when the resulting data structure allows this.
-
Concurrent data structure: different combiners share the same
underlying data structure, and rely on synchronization to correctly
update the data structure when
+=is called.
We’ll look more into the second method, which is more suited for parallel computations.
Conc-Trees
Conc is the parallel counterpart to parallel cons lists, and is used to manipulate data. Let’s compare them to other data structures with an example: the implementation of filter:
Lists are built for sequential computations, and are traversed left to right:
1
2
3
4
5
def filter[T](lst: List[T])(p: T => Boolean): List[T] = lst match {
case x :: xs if p(x) => x :: filter(xs)(p)
case x :: xs => filter(xs)(p)
case Nil => Nil
}
Trees allow parallel computations – their subtrees can be traversed in parallel (this is not a search tree, just a regular tree):
1
2
3
4
5
def filter[T](t: Tree[T])(p: T => Boolean): Tree[T] = t match {
case Node(left, right) => Node(parallel(filter(left)(p), filter(right)(p)))
case Leaf(elem) => if (p(elem)) t else Empty
case Empty => Empty
}
Trees are not good for parallelism unless they are balanced. Let’s devise a data type called Conc, which represents balanced trees:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
sealed trait Conc[+T] {
def level: Int // level of subtree
def size: Int // size of subtree
def left: Conc[T]
def right: Conc[T]
}
case object Empty extends Conc[Nothing] {
def level = 0
def size = 0
}
class Single[T](val x: T) extends Conc[T] {
def level = 0
def size = 1
}
// "Conc class": you can go left < or right >
case class <>[T](left: Conc[T], right: Conc[T]) extends Conc[T] {
val level = 1 + math.max(left.level, right.level)
val size = left.size + right.size
}
In addition, we will define the following invariants for Conc-trees:
- A
<>node can never containEmptyas its subtree. This guards us from sparse trees with too many empty subtrees - The level (read: height) difference between the left and the right subtree of a
<>node is always 1 or less. This ensures that the height is bounded by .
Concatenation is then:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
def <>(that: Conc[T]): Conc[T] = {
if (this == Empty) that
else if (that == Empty) this
else concat(this, that) // delegate real work to concat
// which may reorganize the tree completely
}
def concat[T](xs: Conc[T], ys: Conc[T]): Conc[T] = {
val diff = ys.level - xs.level
if (diff >= -1 && diff <= 1) new <>(xs, ys) // link the trees
else if (diff < -1) {
if (xs.left.level >= xs.right.level) { // Left leaning (left deeper)
val nr = concat(xs.right, ys)
new <>(xs.left, nr)
} else { // Right leaning
val nrr = concat(xs.right.right, ys)
if (nrr.level == xs.level - 3) {
val nl = xs.left
val nr = new <>(xs.right.left, nrr)
new <>(nl, nr)
} else {
val nl = new <>(xs.left, xs.right.left) // new left
val nr = nrr // new right
new <>(nl, nr)
}
}
}
}
Concatenation takes time, where and are the heights of the two trees.
Combiners using Conc-Trees
First we’ll implement +=. To make it efficient (), We extend the Conc-Tree with a new node type:
1
2
3
4
case class Append[T](left: Conc[T], right: Conc[T]) extends Conc[T] {
val level = 1 + math.max(left.level, right.level)
val size = left.size + right.size
}
The Append node has the same structure as a regular <> Conc node, and it has the same level and size; however, we will not impose the balance invariant on it. Trees of arbitrary size difference are allowed. To append a leaf:
1
def appendLeaf[T](xs: Conc[T], y: T): Conc[T] = Append(xs, new Single(y))
This is indeed but creates an unbalanced tree, which means concatenation will be instead of .
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def appendLeaf[T](xs: Conc[T], ys: Single[T]): Conc[T] = xs match {
case Empty => ys
case xs: Single[T] => new <>(xs, ys)
case _ <> _ => new Append(xs, ys)
case xs: Append[T] => append(xs, ys) // delegate work to append
}
@tailrec
private def append[T](xs: Append[T], ys: Conc[T]): Conc[T] = {
if (xs.right.level > ys.level) new Append(xs, ys)
else {
val zs = new <>(xs.right, ys)
xs.left match {
case ws @ Append(_, _) => append(ws, zs)
case ws if ws.level <= zs.level => ws <> zs
case ws => new Append(ws, zs)
}
}
}
We have implemented an immutable data structure with:
- appends
- concatenation
Transforming a Conc-Tree with Append nodes into a regular Conc-Tree should be fairly straightforward from this point on (concatenate trees from append list together). We almost have a functioning combiner; we just need to do a little more work.
The ConcBuffer appends elements into an array of size k. When the array gets full, it is stored into a Chunk node and added into the Conc-tree.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class ConcBuffer[T: ClassTag](val k: Int, private var conc: Conc[T]) {
private var chunk: Array[T] = new Array(k)
private var chunkSize: Int = 0
final def +=(elem: T): Unit = {
if (chunkSize >= k) expand() // push array into conc-tree
chunk(chunkSize) = elem
chunkSize += 1
}
private def expand() {
conc = appendLeaf(conc, new Chunk(chunk, chunkSize))
chunk = new Array(k)
chunkSize = 0
}
final def combine(that: ConcBuffer[T]): ConcBuffer[T] = {
val combinedConc = this.result <> that.result // obtain conc-trees from buffers
new ConcBuffer(k, combinedConc)
}
def result: Conc[T] = { // packs chuck array into the tree, returns resulting tree
conc = appendLeaf(conc, new Chunk(chunk, chunkSize))
conc
}
}
class Chunk[T](val array: Array[T], val size: Int) extends Conc[T] {
def level = 0
}
Chunk nodes are similar to Single nodes, but instead of a single element, they hold an array of elements.
Summary:
-
combineconcatenation - Fast
+=operation -
resultoperation
Part 2: Concurrent programming
A surprising program
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
var a, b = false
var x, y = -1
val t1 = thread {
Thread.sleep(1) // pause for 1ms
a = true
y = if (b) 0 else 1
}
val t2 = thread {
Thread.sleep(1) // pause for 1ms
b = true
x = if (a) 0 else 1
}
t1.join()
t2.join()
assert(!(x == 1 && y == 1))
If we try to mentally simulate all runtime scenarios, where the threads execute in parallel, we can distrniguish three scenarios:
-
y = 1,x = 0 -
y = 0,x = 1 -
y = 0,x = 0
In no scenario do we have x = 1, y = 1. Yet if we run this program, we do encounter this scenario! Let’s rebuild our intuition of concurrent programming.
Every concurrent programming model must answer two questions:
- How to express that two executions are concurrent?
- Given a set of concurrent executions, how can they exchange information (i.e. synchronize)?
In what follows, we will answer these two questions in the context of the JVM concurrency model.
Overview of threads
The thread notation starts a new thread – a concurrent execution.
1
2
3
4
thread {
a = true
y = if (b) 0 else 1
}
The thread function is implemented as follows:
1
2
3
4
5
6
7
def thread(body: =>Unit): Thread = {
val t = new Thread {
override def run() = body
}
t.start()
t
}
We need threads, instead of working directly with the CPU for two reasons:
- Portability: We don’t know which / how many CPUs to address, since this depends on the system
- The number of concurrent entities in a program can be much larger than the number of CPUs
Threads work as an abstraction. A thread image in memory contains:
- Copies of processor registers
- The call stack (~2MB per default)
The operating system eventually assigns threads to processes (the OS guarantees liveness). Two approaches:
- Cooperative multitasking: a program has to explicitly give control (yield) back to the OS (think Windows 3.1)
- Preemptive multitasking: the OS has a hardware timer that periodically interrupts the running thread, and assigns different thread to the CPU (time slices usually ~10 ms)
Some more definitions
Non-deterministic program: Given the same input, the program output is not unique between multiple runs. We want to write deterministic programs!
When join returns, the effects of the terminated thread are visible to the
thread that called join.
To avoid race conditions, we want to ensure that all operations of a function are performed atomically, without another thread reading or writing intermediate results. To do so, we used synchronized blocks, as seen previously (remember how it places a lock on the object).
Monitors
How do we know if a monitor is released? We could do polling (also called busy waiting), but that consumes compute time while waiting. Instead, we can use a notification; indeed, all Monitor objects have the following methods:
-
wait(): suspends the current thread -
notify(): wakes up one other thread waiting on the current object -
notifyAll(): wakes up all other thread waiting on the current object
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class OnePlaceBuffer[Elem] extends Monitor {
var elem: Elem = _; var full = false
def put(e: Elem): Unit = synchronized {
while (full) wait()
elem = e
full = true
notifyAll()
}
def get(): Elem = synchronized {
while (!full) wait()
full = false
notifyAll()
elem
}
}
The fine print:
-
wait,notifyandnotifyAllshould only be called from within asynchronizedonthis -
waitwill release the lock, so other threads can enter the monitor -
notifyandnotifyAllschedule other threads for execution after the calling thread has released the lock (has left the monitor) - On the JVM runtime, it is possible that a thread calling
waitsometimes wakes up even if nobody callednotifyornotifyAll. This is why we usewhileand notif. - In practice, we’ll use
notifyAll()much more often
Memory model
A memory model is a set of rules that defines how and when the writes to memory by one thread become visible to other threads. Consider our introductory example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
var a, b = false
var x, y = -1
val t1 = thread {
Thread.sleep(1) // pause for 1ms
a = true
y = if (b) 0 else 1
}
val t2 = thread {
Thread.sleep(1) // pause for 1ms
b = true
x = if (a) 0 else 1
}
t1.join()
t2.join()
assert(!(x == 1 && y == 1))
When we initially analyzed the introductory example, we assumed that every read and write happens in the program order, and that every read and write goes to main memory. That specific memory model is called the sequential consistency model. More formally:
Consider all the reads and writes to program variables. If the result of the execution is the same as if the read and write operations were executed in some sequential order, and the operations of each individual processor appear in the program order, then the model is sequentially consistent.
Unfortunately, as we saw in our experiment, multicore processors and compilers do not implement the sequential consistency model.
The Java Memory Model (JMM) defines a “happens-before” relationship as follows.
- Program order: Each action in a thread happens-before every subsequent action in the same thread.
- Monitor locking: Unlocking a monitor happens-before every subsequent locking of that monitor.
- Volatile fields: A write to a volatile field happens-before every subsequent read of that field.
-
Thread start: A call to
start()on a thread happens-before all actions of that thread. - Thread termination: An action in a thread happens-before another thread completes a join on that thread.
- Transitivity: If A happens before B and B happens-before C, then A happens-before C.
This means:
- A program point of a thread t is guaranteed to see all actions that happen_before it.
- It may (may) also see actions that can occur before it in the sequential consistency (interleaving) model.
Back to our surprising program:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
var a, b = false
var x, y = -1
val t1 = thread {
Thread.sleep(1) // pause for 1ms
a = true
y = if (b) 0 else 1
}
val t2 = thread {
Thread.sleep(1) // pause for 1ms
b = true
x = if (a) 0 else 1
}
t1.join()
t2.join()
assert(!(x == 1 && y == 1))
This can fail since the two threads operate on their separate copy of memory, and can therefore have outdated information compared to each other.
1
2
3
4
5
6
7
8
9
10
11
12
13
var a, b = false
var x, y = -1
val t1 = thread {
synchronized { a = true }
synchronized { y = if (b) 0 else 1 }
}
val t2 = thread {
synchronized { b = true }
synchronized { x = if (a) 0 else 1 }
}
t1.join()
t2.join()
assert(!(x == 1) && (y == 1))
This would work though! Because synchronized synchronizes the processor caches with main memory at the end of its execution.
In general, a memory model is an abstraction of the hardware capabilities of different computer systems. It essentially abstracts over the underlying system’s cache coherence protocol.
Volatile fields
A volatile field is a field that may change at any time, thanks to another thread. Making a variable @volatile has several effects:
- Reads and writes to volatile variables are never reordered by the compiler.
- Reads and writes are never cached in CPU registers — they go directly to the main memory
- Writes to normal variables, that in the program precede a volatile write W, cannot be moved by the compiler after W
- Reads from normal variables that in the program appear after a volatile read R cannot be moved by the compiler before R.
- Before a volatile write, values cached in registers must be written back to main memory.
- After a volatile read, values cached in registers must be re-read from the main memory.
Writes to @volatile are somewhat expensive (~50% as much as synchronized), but reads are very cheap. But @volatile offers fewer guarantees than synchronized.
Executors
Threads have a lot of nice guarantees, but they are expensive to create. What people do to counteract that is use threads as workhorses that perform the tasks given to them. The number of available threads in a pool is typically some polynomial of the number of cores (e.g. ).
A task presented to an executor is encapsulated in a Runnable object:
1
2
3
trait Runnable {
def run(): Unit // actions to be performed by the task
}
Here’s how a task gets passed to the ForkJoinPool:
1
2
3
4
5
6
7
8
import java.util.concurrent.ForkJoinPool
object ExecutorsCreate extends App {
val executor = new ForkJoinPool
executor.execute(new Runnable {
def run() = log("This task is run async")
})
Thread.sleep(1000)
}
Note that there is no way to await the end of a task like we did with t.join() for threads. Instead, we pause the main thread to give the executor threads time to finish.
The scala.concurrent package defines the ExecutionContext trait and object which is similar to Executor but more specific to Scala.
Execution contexts are passed as implicit parameters to many of Scala’s concurrency abstractions. Here’s how one runs a task using the default execution context:
1
2
3
4
5
6
7
8
import scala.concurrent
object ExecutionContextCreate extends App {
val ectx = ExecutionContext.global
ectx.execute(new Runnable {
def run() = log("This task is run async")
})
Thread.sleep(500)
}
To hide all of this boilerplate, we can put it all in an execute function.
Atomic primitives
synchronized, wait, notify, notifyAll are complex and require support from the OS scheduler. We now look at the primitives in terms of which these higher-level operations are implemented.
An atomic variable is a memory location that supports linearizable operations (meaning that can be executed atomically). Here’s how we can define getUID without synchronized:
1
2
3
4
5
6
7
8
9
import java.util.concurrent.atomic._
object AtomicUid extends App {
private val uid = new AtomicLong(0L)
def getUID(): Long = uid.incrementAndGet()
execute {
log(s"Got a unique id asynchronously: ${getUID()}")
}
log(s"God a unique id: ${getUID()}")
}
AtomicLong offers the atomic operations incrementAndGet() getAndSet(newValue: Long), and compareAndSet(expect: Long, update: Long):
1
2
3
4
5
6
7
8
class AtomicLong {
...
// Functionally equivalent to the following (but in hardware):
def compareAndSet(expect: Long, update: Long) = this.synchronized {
if (this.get == expect) { this.set(update); true }
else false
}
}
compareAndSet, also known as CAS, is a building block on which other linearizable operations are implemented with. It’s often built-in into the hardware, and runs over a hundred cycles or so.
We can implement getUID using CAS directly:
1
2
3
4
5
6
7
@tailrec def getUID(): Long = {
val oldUID = uid.get // read old value from atomic variable
val newUID = oldUID + 1 // compute new value
// Attempt to do a CAS
if (uid.compareAndSet(oldUID, newUID)) newUID // Success!
else getUID() // Some other thread has already done it. Try again
}
Programming without locks
Locks as implemented by synchronized are a convenient concurrency mechanism, but are also problematic (possibility of deadlock, possibility to arbitrarily delay other threads if a thread executes a long-running operation in a synchronized).
With atomic variables and their lock-free operation, we can avoid these problems. We can even simulate locks with atomic variables!
1
2
3
4
5
6
private val lock = new AtomicBoolean(false)
def mySynchronized(body: => Unit): Unit = {
while (!lock.compareAndSet(false, true)) {}
try body
finally lock.set(false)
}
Here’s how we define lock-freedom:
An operation
opis lock-free if, whenever there is a set of threads executingop, at least one thread completes the operation after a finite number of steps, regardless of the speed in which the different threads progress.
Essentially: at least one thread needs to complete the operation in a finite number of steps.
Lazy values
Here’s how scalac currently implements lazy values. It doesn’t use synchronized around the whole block since it’s quite costly, but still must set up some protections:
1
2
3
4
5
6
7
8
9
10
11
@volatile private var x_defined = false
private var x_cached: T = _
def x: T = {
if (!x_defined) this.synchronized {
if (!x_defined) { // this pattern is called double-locking
x_cached = E
x_defined = true
}
x_cached
}
}
The problems with this implementation are:
- It’s not lock-free;
Ecould take arbitrarily long time. - It uses
thisas a lock, which might conflict with application-defined locking. - It’s prone to deadlocks.
The new Scala compiler, dotty, does this instead:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def x: T = {
if (!x_defined) {
this.synchronized {
if (x_evaluating) wait()
else x_evaluating = true
}
if (!x_defined) {
x_cached = E
this.synchronized {
x_evaluating = false
x_defined = true
notifyAll()
}
}
}
}
- The evaluation of
Ehappens outside a monitor, therefore no arbitrary slowdowns - Two short
synchronizedblocks instead of one arbitrary long one - No interference with user-defined locks
- Deadlocks are still possible but only in cases where sequential execution would give an infinite loop
Collections
Operations on mutable collections are usually not thread-safe. The safe way to deal with this is of course to use synchronized, but that often leads to too much blocking. To gain speed, we can use or implement special concurrent collection implementations.
As an example, here’s how concurrent queues could be implemented:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import java.util.concurrent.atomic._
import scala.annotation.tailrec
object ConcQueue {
private class Node[T](@volatile var next: Node[T]) {
var elem: T = _
}
}
class ConcQueue[T] {
import ConcQueue._
private var last = new AtomicReference(new Node[T](null))
private var head = new AtomicReference(last.get)
@tailrec final def append(elem: T): Unit = {
// fiddle with last pointer
val last1 = new Node[T](null)
last1.elem = elem
val prev = last.get
// the following 2 lines differ from the sequential implementation
// append needs to atomically update 2 variables, but CAS can only
// work with 1 variable at a time. So we only use one CAS, and set
// the other assignment when successful
if (last.compareAndSet(prev, last1)) prev.next = last1
else append(elem)
}
@tailrec final def remove(): Option[T] =
if (head eq last) None
else {
val hd = head.get
val first = hd.next
// We just need to do a CAS in case first == null
// This is to ensure that we don't have prev.next == null
// instead of prev.next == last1 in append()
if (first != null && head.compareAndSet(hd, first))
Some(first.elem)
else remove()
}
}
This is not lock-free, but it guarantees that we actually remove. We could also just give up if first == null and return None, which would be lock-free.
Futures
| One | Many | |
|---|---|---|
| Synchronous | Try[T] |
Iterable[T] |
| Asynchronous | Future[T] |
Observable[T] |
Synchronous: Try
1
2
3
4
5
def collectCoins(): List[Coin] = {
if (eatenByMonster(this))
throw new GameOverException("Ooops")
List(Gold, Gold, Silver)
}
The return type here is dishonest, since actions may fail. So if we want to expose the possibility of failure in the types, then we should do T => Try[S] instead of T => S. Our game might now look like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// Making failure evident in types:
abstract class Try[T]
case class Success[T](elem: T) extends Try[T]
case class Failure(t: Throwable) extends Try[Nothing]
trait Adventure {
def collectCoins(): Try[List[Coin]]
def buyTreasure(coins: List[Coin]): Try[Treasure]
}
// Dealing with failure explicitly
val adventure = Adventure()
val coins: Try[List[Coin]] = adventure.collectCoins()
val treasure: Try[Treasure] = coins match {
case Success(cs) => adventure.buyTreasure(cs)
case failure@Failure(e) => failure
}
There are some higher-order functions available that manipulate Try[T]:
1
2
3
4
5
def flatMap[S](f: T=>Try[S]): Try[S]
def flatten[U <: Try[T]]: Try[U]
def map[S](f: T=>S): Try[T]
def filter(p: T=>Boolean): Try[T]
def recoverWith(f: PartialFunction[Throwable,Try[T]]): Try[T]
Asynchronous: Future
Future[T] is a monad that handles exceptions and latency. Usually exceptions aren’t really nice in a multi-threaded context, but Future exists to abstract away from all of our worries. They can asynchronously notify consumers:
1
2
3
4
trait Future[T] {
def onComplete(success: T => Unit, failed: Throwable => Unit): Unit
def onComplete(callback: Observer[T]): Unit
}
Sending a packet across the Atlantic is a situation in which we could use futures; it takes quite a while and we’d like to do other things in the meantime, and still manage failures:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
val socket = Socket()
val packet: Future[Array[Byte]] =
socket.readFromMemory()
val confirmation: Future[Array[Byte]] = packet.onComplete {
case Success(p) => socket.sendToEurope(p)
case Failure(t) => …
}
val socket = Socket()
val packet: Future[Array[Byte]] = socket.readFromMemory()
packet.onComplete {
case Success(p) => {
val confirmation: Future[Array[Byte]] =
socket.sendToEurope(p)
}
case Failure(t) => …
}
This is a bit awkward, we can do much better:
1
2
3
4
5
6
7
// Starts an asynchronous computation
// and returns a future object to which you
// can subscribe to be notified when the
// future completes
object Future {
def apply(body: =>T)(implicit context: ExecutionContext): Future[T]
}
We can then do this elegantly (?):
1
2
3
4
5
6
7
8
9
10
11
12
13
import scala.concurrent.ExecutionContext.Implicits.global
import akka.serializer._
val memory = Queue[EMailMessage](
EMailMessage(from = "Erik", to = "Roland"),
EMailMessage(from = "Martin", to = "Erik"),
EMailMessage(from = "Roland", to = "Martin"))
def readFromMemory(): Future[Array[Byte]] = Future { // LOOK HERE!
val email = queue.dequeue()
val serializer = serialization.findSerializerFor(email)
serializer.toBinary(email)
}
Recover and recoverWith
1
2
def recover(f: PartialFunction[Throwable,T]): Future[T]
def recoverWith(f: PartialFunction[Throwable, Future[T]]): Future[T]
Here’s how we would send packets using futures robustly:
1
2
3
4
5
6
7
8
9
10
11
12
def sendTo(url: URL, packet: Array[Byte]): Future[Array[Byte]] =
Http(url, Request(packet))
.filter(response => response.isOK)
.map(response => response.toByteArray)
def sendToSafe(packet: Array[Byte]): Future[Array[Byte]] =
sendTo(mailServer.europe, packet) recoverWith {
case europeError => // catches everything
sendTo(mailServer.usa, packet) recover {
case usaError => usaError.getMessage.toByteArray
}
}
A sometimes cleaner way of doing it is to provide a fallback:
1
2
3
4
5
6
7
8
9
10
11
12
13
def sendToSafe(packet: Array[Byte]): Future[Array[Byte]] =
sendTo(mailServer.europe, packet) recoverWith {
case europeError => sendTo(mailServer.usa, packet) recover {
case usaError => usaError.getMessage.toByteArray
}
}
def fallbackTo(that: =>Future[T]): Future[T] = {
… if this future fails take the successful result
of that future …
… if that future fails too, take the error of
this future …
}
Implementation of FlatMap on Future
1
2
3
4
5
6
7
8
9
10
trait Future[T] { self =>
def flatMap[S](f: T => Future[S]): Future[S] = new Future[S] {
def onComplete(callback: Try[S] => Unit): Unit =
self onComplete {
case Success(x) =>
f(x).onComplete(callback) // we apply f and if that succeeds, we do callback
case Failure(e) => callback(Failure(e))
}
}
}
The actual implementation is a bit more evolved, as there’s some scheduling involved, but this is the gist of it.
Part 3: Actors
Why Actors?
Actors were invented in 1973 for research on artificial intelligence. Actors were added to the Scala standard library in 2006. Akka, an Actor framework on the JVM with Java and Scala APIs, was created in 2009.
Today, CPUs aren’t really gettting faster as much as they’re getting wider: we use multiple physical and virtual execution cores. To take advantage of these cores, we run multiple programs in parallel (multi-tasking) or we run parts of the same program in parallel (multi-threading).
We saw in the earlier example about bank accounts that if we don’t synchronize our actions, we may “create money” and write incorrect amounts to the balance. To avoid this, we saw how locks work with obj.synchronized { ... }. We also saw that we have to be careful to avoid deadlocks when using these. Since this blocking synchronization may introduce dead-locks, and since it is bad for CPU utilization, we will look into Actors, which are non-blocking objetcts.
What is an Actor?
The Actor Model represents objects and their interactions, resembling human organizations. It is helpful to visualize Actors not as abstract objects on which we call methods, but as people talking to each other. More formally, an Actor:
- is an object with identity
- has a behavior
- only interacts using asynchronous message passing
The Actor Trait
For this, we use the Actor trait in Akka:
1
2
3
4
5
6
type Receive = PartialFunction[Any, Unit]
trait Actor {
def receive: Receive
...
}
It defines one abstract method, receive, which returns a partial function from Any to Unit, describing the response of the Actor to a message. Any message could come in (hence Any), and the Actor may act upon it but cannot return anything, since the sender is long gone (hence Unit).
A simple, stateful Actor
Let’s implement the Actor trait in an example class:
1
2
3
4
5
6
7
class Counter extends Actor {
var count = 0
def receive = {
case "incr" => count += 1
case ("get", customer: ActorRef) => customer ! count
}
}
If the counter gets the message "incr", it simply increments the counter. But our actor can also send messages to addresses they know (in Akka, they are ActorRefs). If the customer (the actor that sends the message) sends a ("get", customer: ActorRef) tuple, our counter will send the count back. Note that the exclamation mark ! is used to send messages in Akka (it means “fire and forget”, also known as tell).
How messages are sent
Let’s look at more parts of the Actor trait:
1
2
3
4
5
6
7
8
9
trait Actor {
implicit val self: ActorRef // each Actor knows its own address
def sender: ActorRef // the ActorRef of sender of the received message
}
trait ActorRef {
def !(msg: Any)(implicit sender: ActorRef = Actor.noSender): Unit // implicitly picks up self as the sender
def tell(msg: Any, sender: ActorRef) = this.!(msg)(sender) // Java syntax
}
With this API in mind, we can make our previous example a little nicer:
1
2
3
4
5
6
7
class Counter extends Actor {
var count = 0
def receive = {
case "incr" => count += 1
case "get" => sender ! count
}
}
The Actor’s Context
It can do more things than just send messages: it can create other Actors, change its behavior, etc. The Actor type describes the behavior, while the execution is done by its ActorContext:
1
2
3
4
5
6
7
8
9
10
trait ActorContext {
def become(behavior: Receive, discardOld: Boolean = true): Unit
def unbecome(): Unit
...
}
trait Actor {
implicit val context: ActorContext
...
}
Each Actor has a stack of behaviors, and the topmost one is always the active one. The default mode of become is to replace the top of the stack with a new behavior, but it can also be used to push, and unbecome to pop behaviors. Let’s see it in action by reformulating our Counter Actor:
1
2
3
4
5
6
7
class Counter extends Actor {
def counter(n: Int): Receive = { // takes an argument for the current state
case "incr" => context.become(counter(n + 1)) // change behavior to become counter of n+1
case "get" => sender ! n // reply with current value
}
def receive = counter(0) // initialize it at 0
}
Functionally, it is equivalent to the previous version. It looks a bit like a tail-recursive function because it calls itself, but it is asynchronous, since context.become only evaluates when the next message is processed. There are advantages in this version though:
- State change is explicit; there’s only one place where the state is changed
- State is scoped to current behavior; there are no variables that can be left in an unkown state
Creating and Stopping Actors
1
2
3
4
5
trait ActorContext {
def actorOf(p: Props, name: String): ActorRef
def stop(a: ActorRef): Unit
...
}
Actors are always created by actors; that means that they always form a hierarchy. stop is often applied to self, meaning that the actor wants to terminate. We can now define an Actor application:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import akka.actor.Actor
import akka.actor.Props
class Main extends Actor {
val counter = context.actorOf(Props[Counter], "counter")
counter ! "incr"
counter ! "incr"
counter ! "incr"
counter ! "get"
def receive = {
case count: Int =>
println(s"count was $count")
context.stop(self)
}
}
Note that in order to run this in an IDE, we’ll need to set the main class to akka.Main and give it as first argument the full class name of the Actor class which is to be instantiated.
Message Processing
Access to the state of Actors is only possible by exchanging messages. Messages can be sent to to known addresses (ActorRef):
- Every actor knows its own address (
self) - Creating an actor returns its address (not the Actor object)
- Addresses can be sent with messages (
sender, for instance, which is captured automatically)
Actors are completely independent agents of computation:
- Local execution, no notion of global synchronization
- All actors run fully concurrently
- Message passing is the only way to interact
- Message passing is a one-way communication (an Actor doesn’t know if the sent message has been sent or processed)
An actor is single-threaded
- Messages are received sequentially
- Behavior change is effective before processing the next message
- Processing one message is the atomic unit of execution
This has the same benefits of synchronized methods, but blocking is replaced by enqueuing messages for later execution.
Revisiting the Bank Account Example
It’s good practice to define an Actor’s messages (both what it can receive and send) in the Actor’s companion object:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
object BankAccount {
case class Deposit(amount: BigInt) {
require(amount > 0) // always positive
}
case class Withdraw(amount: BigInt) {
require(amount > 0) // always positive
}
case object Done
case object Failed
}
class BankAccount extends Actor {
import BankAccount._
var balance = BigInt(0)
def receive = {
case Deposit(amount) =>
balance += amount
sender ! Done
case Withdraw(amount) =>
balance -= amount
sender ! Done
case _ => sender ! Failed
}
}
// Use a different actor for the logic of the transfer
// (since the bank account shouldn't have to deal with that logic)
object WireTransfer {
case class Transfer(from: ActorRef, to: ActorRef, amount: BigInt)
case object Done
case object Failed
}
class WireTransfer extends Actor {
import WireTransfer._
def receive = {
case Transfer(from, to, amount) =>
from ! BanckAccount.Withdraw(amount) // send message
context.become(awaitWithdraw(to, amount, sender)) // await result of withdraw activity
}
def awaitWithdraw(to: ActorRef, amount: BigInt, client: ActorRef): Receive = {
case BankAccount.Done =>
to ! BankAccount.Deposit(amount)
context.become(awaitDeposit(client))
case BankAccount.Failed =>
client ! Failed
context.stop(self)
}
def awaitDeposit(client: ActorRef): Receive = {
case BankAccount.Done =>
client ! Done
context.stop(self)
}
}
Message Delivery Guarantees
All communication is inherently unreliable — we can’t know for sure that the message was actually received. As a fix, we can set the following resending policies:
-
at-most-once: sending once delivers times. This can be done without keeping any state -
at-least-once: resending until acknowledged delivers times. The sender needs to buffer the message in case it needs to resend -
exactly-once: processing only first reception delivers 1 time. This requires a buffer and keeping track of which messages have been processed.
Luckily for us, messages support reliability:
- All messages can be persisted, meaning that we can take a copy and store it in some persistent storage.
- Messages can include unique IDs
- Delivery can be retried until successful
But this only works if we use acknowledgements from the receiver. We can make the WireTransfer reliable by:
- Logging activities of
WireTransferto persistent storage - Giving each transfer a unique ID
- Adding IDs to
WithdrawandDeposit - Storing IDs of completed actions within BankAccount
Message Ordering
If an actor sends multiple messages to the same destination, they will not arrive out of order (this is Akka-specific). Other than that, message ordering to different receivers is not prescribed by the Actor model.
Designing Actor Systems
Imagine giving the task to a group of people, dividing it up. Consider the group to be of very large size, and the people to be easily replaceable (since Actors have quite low overhead, we can make plenty of them). Draw a diagram with how the task will be split up between the people and the communication lines between them. For example, if we want to build a web crawler, we might use:
- A web client which turns a URL into a HTTP body asynchronously
- A
Getteractor for processing the body - A
Controllerwhich spawnsGetters for all links encountered - A
Receptionistmanaging oneControllerper request
The videos goes into a long example (seriously, 40 minutes), but here are the important lessons:
- A reactive application is non-blocking and event-driven top to bottom
- Actors are run by a dispatcher (potentially shared) which can also run
Futures - Prefer immutable data structures, since they can be shared
- Do not refer to actor state from code running asynchronously
- Prefer
context.becomefor different states, with data local to the behavior
Actor-Based Logging
In Akka, you can log like this:
1
2
3
4
5
class A extends Actor with ActorLogging {
def receive = {
case msg => log.debug("received message: {}", msg)
}
}
Logging includes IO which can block indefinitely, but Akka’s logging passes that task to dedicated actors. You can set the level of debugging by setting akka.loglevel=DEBUG (other levels are debug, info, warning, error).
Handling Timeouts
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import scala.concurrent.duration._
class Controller extends Actor with ActorLogging {
context.setReceiveTimeout(10.seconds) // reset after each message processing
...
def receive = {
case Check(...) => ...
case Getter.Done => ..
case ReceiveTimeout => children foreach (_ ! Getter.Abort) // abort all children
}
}
class Getter {
def receive = {
...
case Abort => stop()
}
def stop(): Unit = {
context.parent ! Done
context.stop(self)
}
}
Testing Actor Systems
Tests can only verify message passing. Say we have an Actor called Toggle that responds with happy and sad alternatively:
1
2
3
4
5
6
7
8
9
10
implicit val system = ActorSystem("TestSys")
val toggle = system.actorOf(Props[Toggle])
val p = TestProbe()
p.send(toggle, "How are you?")
p.expectMsg("happy")
p.send(toggle, "How are you?")
p.expectMsg("sad")
p.send(toggle, "unkown")
p.expectNoMsg(1.second)
system.shutdown() // otherwise the thread keeps running
We can also run a test within a TestProbe:
1
2
3
4
5
6
7
8
new TestKit(ActorSystem("TestSys")) with ImplicitSender {
val toggle = system.actorOf(Props[Toggle])
toggle ! "How are you?"
expectMsg("happy")
toggle ! "How are you?"
expectMsg("sad")
...
}
Sometimes, we need to test an Actor with real-life dependencies (accessing a DB, a production web service, etc). We don’t want to do testing with these, so the solution is to use dependency injection, or overridable factory methods.
When testing hierarchies, it’s good practice to verify the leaves, and working your way up.
Failure Handling with Actors
Resilience demands:
- Containment of failure: failure is isolated, can’t spread to other components. This happens by design of the model, since actors are fully encapsulated objects
- Delegation of failure: failure cannot be handled by the failed component, since it is presumably compromised, so the failure must be handled by another actor.
This means that another Actor needs to decide whether the failed Actor is terminated or restarted. If it needs to be able to restart the failed Actor, then it is both the supervisor and the parent. In other words, the supervision and parental hierarchy are the same, which means failure is passed to the parent. In Akka, we call this mandatory parental supervision.
How does this supervision hierarchy translate to code?
1
2
3
4
5
6
7
8
9
10
11
class Manager extends Actor {
override val supervisorStrategy = OneForOneStrategy() { // val not def (define it once)
case _: DBException => Restart // reconnect to DB
case _: ActorKilledException => Stop
case _: ServiceDownException => Escalate // can't fix it itself, so escalate
}
...
context.actorOf(Props[DBActor], "db")
context.actorOf(Props[ImportantServiceActor], "service")
...
}
Note that failure is sent and processed like a message, so we can do everything we usually can with it. However, to fix the problem Stop, Restart and Escalate are the only available tools.
Strategies
There are two strategies:
-
OneForOneStrategy: always deal with each child Actor in isolation -
AllForOneStrategy: decision applies to all children (children need to live and die together (that’s dark)).
Each strategy can be configured to include a simple rate trigger:
1
2
3
OneForOneStrategy(maxNrOfRestarts = 10, withinTimeRange = 1.minute) {
case _: DBException => Restart // will turn into Stop
}
Restarts
In Akka, the ActorRef stays valid after a restart (this is not the case in Erlang, for instance). This means other Actors can keep interacting with the failed Actor once the failure has been dealt with.
What does a restart really mean?
- Expected error conditions are typically handled explicitly within the Actor
- Unexpected errors indicate invalidated actor state. In this case, a restart restores the initial state.
Lifecycle Hooks
When an Actor starts, restarts and stops, we can define different hooks to be run, whose defaults are:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
trait Actor {
def preStart(): Unit = {}
// reason is the thrown exception.
// message is what was being processed at the time.
def preRestart(reason: Throwable, message: Option[Any]): Unit = {
// Default behavior is to stop all children, since they are
// considered part of the Actor's state:
context.children foreach (context.stop(_))
postStop()
}
def postRestart(reason: Throwable): Unit = {
preStart()
}
def postStop(): Unit = {}
}
Any Actor can of course override these methods. If, when overriding preRestart, we do not stop child actors, the context will recursively restart them.
Lifecycle Monitoring
From the outside, the only observable transition occurs when an Actor stops. After a stop, there will be no more responses — but how do we distinguish an Actor that has been terminated from one that just doesn’t respond anymore? In Akka, there exists a feature called DeathWatch:
- An Actor registers its interest using
context.watch(target) - It will receive a
Terminated(target)message when the target stops - It will not receive any direct messages from
targetthereafter (indirect messages going through intermediate actors may still be en route, but not direct ones)
The DeathWatch API provides two methods:
1
2
3
4
5
6
7
8
9
trait ActorContext {
def watch(target: ActorRef): ActorRef
def unwatch(target: ActorRef): ActorRef
...
}
case class Terminated private[akka] (actor: ActorRef)
(val existenceConfirmed: Boolean, val addressTerminated: Boolean)
extends AutoReceiveMessage with PossiblyHarmful
Terminated is a special message. You can’t declare it yourself as it’s private to Akka. If you’re watch an existing Actor, Akka will send Terminated(...)(true) when it stops. If you try to watch a non-existing (or no-longer existing) Actor, Akka will reply immediately with Terminated(...)(false).
Terminated extends AutoReceiveMessage which means that they’re handled by the Actor context, and that Terminated messages cannot be forwarded.
Terminated messages are PossiblyHarmful.
The Chlidren List
Each actor maintains a list of the actors it created:
1
2
3
4
5
trait ActorContext {
def children: Iterable[ActorRef] // list of all
def child(name: String): Option[ActorRef] // query for one
...
}
- When
context.actorOfreturns, the child has been entered into the list - When
Terminatedis received, the child has been removed from the list - Even if we don’t use DeathWatch, the child is removed (but no
Terminatedis sent)
The Error Kernel
It’s good practice to keep important data near the root, and delegate risk to the leaves. This way, when an Actor restarts, the effect will be rather localized (it won’t have to restart children). This is called the Error Kernel pattern.
EventStream
So far, we’ve stated that Actors can direct messages only at known addresses. But the reality is that another option exists: it’s the equivalent of shouting something in a room full of people. The EventStream allows publication of messages to an unknown audience. Every Actor can optionally subscribe to (parts of) the EventStream.
1
2
3
4
5
6
trait EventStream {
def subscribe(subscriber: ActorRef, topic: Class[_]): Boolean // topic is a Java class object
def unsubscribe(subscriber: ActorRef, topic: Class[_]): Boolean
def unsubscribe(subscriber: ActorRef): Unit
def publish(event: AnyRef): Unit
}
An example in code:
1
2
3
4
5
6
7
8
9
10
class Listener extends Actor {
context.system.eventStream.subscribe(self, classOf[LogEvent])
def receive = {
case e: LogEvent => ...
}
// It is good practice to unsubscribe from all events in postStop:
override def postStop(): Unit = {
context.system.eventStream.unsubscribe(self)
}
}
Unhandled Messages
Actor.Receive is a partial function, so the behavior may not apply. Unhandled messages are passed into the unhandled method, whose default behavior is:
1
2
3
4
5
6
7
8
trait Actor {
...
def unhandled(message: Any): Unit = message match {
case Terminated(target) => throw new DeathPactException(target)
case msg =>
context.system.eventStream.publish(UnhandledMessage(ms, sender, self))
}
}
The supervisor’s default response to a DeathPactException is to send a Stop command. All other messages are published, so we could for example register a listener to log unhandled messages.
Persistent Actor State
The Error Kernel pattern allows us to keep important Actors relatively safe, but there are cases where we cannot lose data at all. Losing state due to a restart is not the only thing that can happen: we could also lose data due to buggy software or hardware, or due to a system failure. If we need to keep state across all these failure scenarios, then we need to make sure it’s stored on a harddrive for instance.
There are two possibilites for persisting state:
- Have the Actor mirror a persistent storage location, and do in-place updates (replacements) of both.
- Recovery of latest state in constant time
- Data volume depends on number of records, not their change rate
- Save the chain of changes that are applied to state, in an append-only fashion (this is like an event log)
- History can be replayed, audited or restored
- Some processing errors (bugs) can be corrected retroactively
- Additional insight can be gained on the process (a user’s behavior on a shopping site, for example)
- Writing an append-only stream optimizes IO bandwidth
- Changes are immutable and can freely be replicated
If you only want to persist the state of an actor, and put an upper bound on the time recovery may take, you can use snapshots. Snapshots combine both of the above methods by tying a current state to a change. That way you don’t have to replay all changes to find the final state, you can just recover from the latest saved state and replay the few changes that happened after that snapshot.
How do Actors actually persist changes? There are two ways of doing it:
-
Command-Sourcing: We make sure that the Actor doesn’t lose any command by persisting the command before processing it (same goes for acknowledgements). During recovery, all commands are replayed to recover the state. During this replay, the Actor may send messages in response, but those are rerouted through a persistent
Channelwhich discards messages that have already been sent to other actors. - Event-Sourcing: The focus isn’t on replaying the commands, but instead on saving and applying the change requests (“events”). We don’t save what we want to happen (commands) to the log, we save what has happened (events). During a replay, the Actor doesn’t need to see the commands again, just the events.
Here’s an example of this — an actor which processes blog posts, with a daily quota for each user:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
sealed trait Event
case class PostCreated(text: String) extends Event
case object QuotaReached extends Event
case class State(posts: Vector[String], disabled: Boolean) {
def updated(e: Event): State = e match {
case PostCreated(text) => copy(posts = posts :+ text)
case QuotaReached => copy(disabled = true)
}
}
class UserProcessor extends Actor {
var state = State(Vector.empty, false)
def receive = {
case NewPost(text) =>
if (!state.disabled)
emit(PostCreated(text), QuotaReached)
case e: Event =>
state = state.updated(e)
}
def emit(events: Event*) = ... // send to log
}
There’s a problem with this, though: we might get a new post while we’re sending the previous one to the log (writing to disk does take some time), in which case it will pass the condition in the if statement, and will be added anyway. This is a general problem with applying and then persisting: it leaves the actor in a stale state.
If we persist and then apply, then we don’t have that problem, but we might have trouble regenerating after a system-wide crash, as the last state may not have been fully persisted yet.
So it seems like we need to choose between correct persistence and correct behavior — but there is a third option: do not process new messages while waiting for persistance. However this option comes at a performance cost, as we reduce performance, augment latency and lower throughtput.
The ability to postpone messages which cannot yet be handled is provided by the Stash trait in Akka:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class UserProcessor extends Actor with Stash {
var state: State = ...
def receive = {
case NewPost(Text) if !state.disabled =>
emit(PostCreated(text), QuotaReached)
// Then, it changes it behavior:
// it waits for the 2 events to be persisted
context.become(waiting(2), discardOld = false)
}
def waiting(n: Int): Receive = { // while we're waiting, we:
case e: Event => // we process only events
state = state.updated(e)
if (n == 1) { // if it's the last one we were waiting for:
context.unbecome() // pop behavior from stack
unstashAll() // allow all messages that in the meantime to be reprocessed.
}
else context.become(waiting(n-1))
case _ => stash() // anything that isn't an event is stashed.
}
}
What about when we need to interact with some outside service that isn’t based on actors? Say we charge money from a credit card for each post, do we first charge the card (perform) and then persist? Or the other way?
- If we perform before persisting, we get at least one bank payment (the user may be charged again if the system crashes before the persisting happened).
- If we persist before performing, we get at most one bank payment
There’s no “better option” — what to choose depends on the application and business model.
In summary:
- Actors can persist incoming messages or generated events.
- Events are immutable, so they can be replicated, and used to inform other components since they can be read many times
- Recovery replays past commands or events; snapshots reduce this cost
- Actors can defer handling certain messages by using the
Stashtrait
Actors are Distributed
Actors are inherently distributed. Normally, we run them on different CPUs on the same system, but nothing stops us from running them on different network-connected hosts. But it does take some effort to make Actors agree on a common truth. We call this eventual consistency.
The Impact of Network Communication
Compared to running the code locally, running it on a network means:
- Data can only be shared by value (not by name), since a copy has to be made.
- Bandwidth is lower
- Latency is higher
- Partial failures may happen: packets may get lost in transfer
- Data corruption can also happen (think 1 corruption by TB sent)
Distributed computing breaks many assumptions made by the synchronous programming model.
Some things still hold, though. Actors are model a network locally (instead of modelling local mechanisms on the network), so message loss is a part of what we deal with, and they are so isolated that they act like different hosts on a network would.
All of this means that the effort of writing a distributed program using Actors is basically the same of writing a local variant (!!). The code itself won’t look much different.
Actor Path
Actors are Location Transparent, which means that their location simply is hidden behind an ActorRef. We know that Actors form a hierarchy. Behind the hood, they have a path corresponding to the URI format:
1
2
3
val system = ActorSystem("HelloWorld")
val ref = system.actorOf(Props[Greeter], "greeter")
println(ref.path) // prints: akka://HelloWorld/user/greeter
Every Actor is like a folder in this URI. akka://HelloWorld/ is called the authority, and user/greeter is the path. Let’s look at a remote address example: akka.tcp://[email protected]:6564/user/greeter is a /user/greeter Actor. It’s in an Akka system using the TCP protocol, also named HelloWorld, accessible at 10.2.4.6 at port 6565. An Actor has at least one such URI (but can have multiple, i.e. if it’s reachable on multiple IP addresses or ports).
It is worth noting that an ActorPath is not an ActorRef:
-
ActorPathis the full name, whether the Actor exists or not- Can only optimistically send a message
- Cannot be watched (we don’t know if it exists)
-
ActorRefpoints to one Actor which was started (an incarnation).- Can be watched
- Example:
akka://HelloWorld/user/greeter#43428347. It looks like a path, but has an extra UID
To resolve an ActorPath in remote system, it is necessary to talk to Actors that we haven’t created ourselves, and for which you have no means to acquire an ActorRef. You just know which the ActorPath (host, port, etc.). To resolve an Actor, we can just send a Resolve(path) message to a Resolver Actor, which is defined as:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import akka.actor.{ Identify, ActorIdentity }
case class Resolve(path: ActorPath)
case class Resolved(path: ActorPath, ref: ActorRef)
case class NotResolved(path: ActorPath)
class Resolver extends Actor {
def receive = {
case Resolve(path) =>
context.actorSelection(path) ! Identify((path, sender))
// context.actorSelection constructs something we can send to
case ActorIdentity((path, client), Some(ref)) => // actor alive
client ! Resolved(path, ref)
case ActorIdentity((path, client), None) => // no such actor alive
client ! NotResolved(path)
}
}
Every Actor automatically supports akka.actor.Identify, and reply with an ActorIdentity.
Relative actor paths also exist:
1
2
3
context.actorSelection("child/grandchild") // going down in the hierarchy
context.actorSelection("../sibling") // going up in the hierarchy
context.actorSelection("/user/controllers/*") // from the root, and wildcard
Clusters
A cluster is a set of nodes about which all members are in agreement. These nodes can then collaborate on a common task. A single node can declare itself a cluster (join itself). It can then join a cluster:
- A request is sent to any member
- Once all current members know about the new node, it is declared part of the cluster
Information is spread using a gossip/epidemic protocol, each Actor spreading the message to its neighbors.
To set up a cluster, there are a few prerequisites. First, we have an SBT dependency:
1
"com.typesafe.akka" %% "akka-cluster" % "2.2.1"
Then, we need some configuration enabling the cluster module, in application.conf:
1
2
3
4
5
akka {
actor {
provider = akka.cluster.ClusterActorRefProvider
}
}
Alternatively, we can use -Dakka.actor.provider=.... Now onto some code; this is the only full example I’ve included, as I think it covers the whole subject pretty well. We’ll take a look at how to implement work routing to different Controller workers, again to grab some URLs. The following will start a single-node cluster on port 2552:
1
2
3
4
5
6
7
8
9
10
11
12
class ClusterMain extends Actor {
val cluster = Cluster(context.system)
cluster.subscribe(self, classOf[ClusterEvent.MemberUp]) // new members
cluster.join(cluster.selfAddress)
def receive = {
case ClusterEvent.MemberUp(member) =>
if (member.address != cluster.selfAddress) {
// someone joined
}
}
}
If we code a second node, we need a seperate port, using akka.remote.netty.tcp.port = 0.
1
2
3
4
5
6
7
8
9
10
11
class ClusterWorker extends Actor {
val cluster = Cluster(context.system)
cluster.subscribe(self, classOf[ClusterEvent.MemberRemoved])
val main = cluster.selfAddress.copy(port = Some(2552))
cluster.join(main)
def receive = {
case ClusterEvent.MemeberRemoved(m, _) => // main program shuts down
if (m.address == main) context.stop(self) // shut this down as well
}
}
How do we route work to cluster members? We create a Receptionist:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
class ClusterReceptionist extends Actor {
val cluster = Cluster(context.system)
cluster.subscribe(self, classOf[MemberUp])
cluster.subscribe(self, classOf[MemberRemoved])
override def postStop(): Unit = {
cluster.unsubscribe(self)
}
def receive = awaitingMembers
val awaitingMembers: Receive = {
// Check if there are other nodes, and change to active if yes:
case current: ClusterEvent.CurrentClusterState =>
val addresses = current.members.toVector map (_.address)
val notMe = addresses filter (_ != cluster.selfAddress)
if (notMe.nonEmpty) // if there's another node in the cluster
context.become(active(notMe)) // change to active mode
// Typically though, there are no other nodes in the beginning,
// so we must wait for new ones:
// If we get a new member, different from ourself:
case MemberUp(member) if member.address != cluster.selfAddress =>
// change to active state with new member:
context.become(active(Vector(member.addresses)))
case Get(url) => sender ! Failed(url, "no nodes available")
}
def active(addresses: Vector[Address]): Receive = {
// New member that isn't ourself:
case MemberUp(member) if member.address != cluster.selfAddress =>
context.become(active(addresses :+ member.address)) // add him
// Member removed:
case MemberRemoved(member, _) =>
// Filter the removed member out:
val next = addresses filterNot (_ == member.address)
if (next.isEmpty) // if it was the last one, go back to awaiting
context.become(awaitingMembers)
else // otherwise, stay active (with the reduced list)
context.become(active(next))
// Get request comes in, and we have enough resources to handle it:
case Get(url) if context.children.size < addresses.size =>
val client = sender // COPY client, since Customer will be async
val address = pick(addresses) // pick one randomly from the list
// create new Customer Actor:
context.actorOf(Props(new Customer(client, url, address)))
// Get request comes in, and we don't have the resources to handle it:
case Get(url) =>
sender ! Failed(url, "too many parallel queries")
}
}
There’s a Customer Actor that makes sure the given url is retrieved, but the work is supposed to be performed at a remote node. For that, it creates a Controller:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class Customer(client: ActorRef, url: String, node: Address) extends Actor {
// self is implicitly sent as sender.
// From the outside, we want to make it look like the sender is
// Receptionist, not this intermediary Actor.
implicit val s = context.parent
override val supervisorStrategy = SupervisorStrategy.stoppingStrategy
// Deploy with remote scope on the given node, not locally:
val props = Props[Controller].withDeploy(Deploy(scope = RemoteScope(node)))
val controller = context.actorOf(props, "controller")
context.watch(controller)
context.setReceiveTimeout(5.seconds)
controller ! Controller.Check(url, 2)
def receive = ({ // supervise Controller
case ReceiveTimeout =>
context.unwatch(controller)
client ! Receptrionist.Failed(url, "controller timed out")
case Terminated(_) =>
client ! Receptionist.Failed(url, "controller died")
case Controller.Result(links) =>
context.unwatch(controller)
client ! Receptionist.Result(url, links)
}: Receive) andThen (_ => context.stop(self)) // recursive stop, controller stops too
}
The Controller is the worker; its parent is the Customer.
Eventual Consistency
We’ve now seen how Clusters work. What’s evident is that everything takes time: node joining takes time to disseminate the information among the rest of the cluster, it takes time until the welcome message arrives, etc. The decisions aren’t taken immediately, they’re taken eventually.
When we made a bank account thread safe, we made it strongly consistent: after an update, all subsequent reads will return the updated value.
We can also define weak consistency: after an update, certain conditions need to be met before the update is visible — in other words, it takes a little while before our update can be read. This is the inconsistency window.
Eventual consistency is a special kind of weak consistency. It states that once no more updates are made to an object, after a while (once everyone has communicated the value) reads will all return the last written value.
Let’s try it out with a simple Actor.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
case class Update(x: Int) // gives a new value
case object Get // get request
case class Result(x: Int) // result reply type
case class Sync(x, timestamp: Long) // synchronization messages
case object Hello // to learn of other actors' existence
class DistributedStore extends Actor { // eventually consistent
var peers: List[ActorRef] = Nil
var field = 0
var lastUpdate = System.currentTimeMillis()
def receive = {
case Update(x) =>
field = x
lastUpdate = System.currentTimeMillis()
peers foreach (_ ! Sync(field, lastUpdate))
case Get => sender ! Result(field)
case Sync(x, timestamp) if timestamp > lastUpdate =>
field = x
lastUpdate = timestamp
case Hello =>
peers ::= sender // append new sender
sender ! Sync(field, lastUpdate)
}
}
This should clarify the concept of eventual consistency a bit. Updates are taken into account, but eventually the “truth” propagates throughout the peer network.
Actors and eventual consistency are closely tied:
- An actor forms an island of consistency, surrounded by an ocean of non-determinism
- Collaborating actors can at most be eventually consistent — they can’t be strongly consistent, since messages take time to be sent. Note that eventual consistency isn’t a given, it doesn’t come automatically: some work still needs to be done to ensure this.
- Event consistency requires us to disseminate all updates to interested parties eventually (there needs to be a resend mechanism).
- The shared data structures need to be suitable for that. We can for instance use CRDTs (Commutative Replicated Data Types, a class of data types) .
Part 4: Big Data Analysis with Scala and Spark
This part focuses on how to map some of the abstractions that we’ve learned so far to computations on multiple machines over massive datasets. Why Scala, why Spark? The alternatives for data processing, like R, Python and MATLAB don’t scale when our datasets get too large to fit into memory. Once we get more than a few gigabytes, we have to re-implement everything in some other language or system, like Spark or Hadoop.
Why Spark over Hadoop?
- The functional paradigm scales very well
- Spark is more expressive: APIs are modeled after Scala collections, they look like functional lists.
- Spark is performant, in terms of running time (sometimes x120), but also in terms of dev productivity. It’s also interactive, which Hadoop isn’t
- Good for data science, since it enables iteration (most data science problems involve iteration). Once data is in memory, Spark applies all functional iterations, instead of spending time needlessly doing IO.
Throughout this part, we’ll use the Apache Spark framework for distributed data-parallel programming. Spark implements a data model called Resilient Distributed Datasets (RDDs), the distributed counterpart of a parallel collection.
Data-Parallel to Distributed Data-Parallel
In this section, we’ll bridge the gap between parallelism with shared memory and distributed data parallelism. Let’s look at an example for shared memory:
1
val res = jar.map(jellyBean => doSomething(jellyBean))
We’ve seen before that we have a sort of collection abstraction going on, where if jar is a parallel array, then the data is split up between workers/threads, which combine when they’re done (if necessary) — but this is done under the hood. In the distributed case, we need to split the data over several nodes (instead of several workers), which independently operate on data shards in parallel, and combine when done, and we now have to worry about network latency between workers. What would that look like?
1
val res = jar.map(jellyBean => doSomething(jellyBean))
It’s the same! Just like before, we can keep collections abstraction over distributed data-parallel execution. So a lot of what we’ve learned can now be applied (including problems, i.e. with non-associative reduction operations), but we also have latency as an extra problem.
Latency
Latency cannot be masked completely, we always have to think about it. It will be an important aspect that also impacts the programming model. Latency of a packet from the US to Europe and back to the US is approximately 150ms, compared to 100ns for reading from memory, so it’s about a million times slower. Network is super slow, so slow that it changes how we must work.
Hadoop has fault-tolerance (this is important because once you have 1000 nodes, crashes and network faults happen), but it comes at a cost: between each map and reduce step, in order to recover from potential failures, Hadoop/MapReduce shuffles its data and writes intermediate data to disk. This is also very slow. Spark manages to keep fault-tolerance, but reduces latency by keeping all data immutable and in-memory. Then fault tolerance is achieved by replaying functional transformations over the original dataset.
RDDs, Spark’s Distributed Collections
RDDs look a lot like immutable sequential or parallel Scala collections, and make a lot of use of higher-order functions.
1
2
3
4
5
6
7
8
9
10
abstract class RDD[T] {
def map[U](f: T => U): RDD[U] = ...
def flatMap[U](f: T => TraversableOnce[U]): RDD[U] = ...
def filter(f: T => Boolean): RDD[T] = ...
def reduce(f: (T, T) => T): T = ...
def fold(z: T)(op: (T, T) => T): T = ...
def aggregate[U](z: U)(seqop: (U, T) => U, combop: (U, U) => U): RDD[U] = ...
def distinct(): RDD[T] = ... // duplicates removed
...
}
Every definition closely resembles the regular Scala Collection definition, except for aggregate, which takes z by value instead of CBN like in normal Scala. This is because copies need to be made, we can’t send a reference to z since it may be sent over the network to another node.
Let’s try an example. Given val encyclopedia: RDD[String], say we want to search all of encyclopedia for mentions of EPFL, and count the number of pages mentioning it:
1
val res = encyclopedia.filter(page => page.contains("EPFL")).count()
Let’s try word counting (this is like “Hello World” for large-scale data):
1
2
3
4
5
6
// Create RDD:
val rdd = spark.textFile("hdfs://...") // more on this later
val count = rdd.flatMap(line => line.split(" ")) // separate lines into words
.map(word => (word, 1)) // include something to count
.reduceByKey(_ + _) // sum up the 1s in the pairs
reduceByKey is a special Spark method that we’ll talk more about later.
Creating RDDs
RDDs can be created in two ways:
- Transforming an existing RDD: using higher order functions, for instance
-
From a
SparkContextorSparkSessionobject:SparkContext(now renamed toSparkSession) is how we handle the Spark cluster. It represents the connection between the Spark cluster and our running application, and uses a handful of methods to create and populate a new RDD:-
parallelize: convert local Scala collection to an RDD -
textFile: read a text file from HDFS or local file system and returnRDD[String]
-
Transformations and Actions
A reminder of transformers and accessors:
-
Transformers: return new collections as results (
map,filter,flatMap,groupBy, …) -
Accessors: return single value as result (
reduce,fold,aggregate)
In Spark, we have transformations instead of transformers, and actions instead of accessors. Why do we use a different name, when there’s seemingly no difference? Because there’s a new, enormous difference: Transformations are lazy, actions are eager: for transformations, the resulting RDD is not immediately computed, while the result of actions are. Laziness/eagerness is how we can limit network communication using the programming model, so this is important.
Let’s look at an example:
1
2
3
4
// Let sc be a SparkContext
val largeList: List[String] = ...
val wordsRdd: RDD[String] = sc.parallelize(largeList)
val lengthsRdd: RDD[Int] = wordsRdd.map(_.length)
At this point, the RDD hasn’t changed! This is because the transformations are deferred; all we get back is an address to an RDD that doesn’t yet exist. To kick off the computation and wait for its result, we can add an action:
1
val totalChars = lengthsRdd.reduce(_ + _)
This is important to remember: nothing happens until we call an action.
A few common transformations:
-
map[B](f: A => B): RDD[B]: applyfto each element in the RDD and return RDD of the result -
flatMap[B](f: A => TraversableOnce[B]): RDD[B]: applyfto each element in the RDD and return an RDD of the contents of what the iterators returned. -
filter(pred: A => Boolean): RDD[A]: Applypredto each element and returnRDDof elements passing the predicate condition -
distinct(): RDD[B]: return RDD with duplicates removed
Transformations on two RDDs:
-
union(other: RDD[T]): RDD[T]: return an RDD containing elements from both RDDs -
intersection(other: RDD[T]): RDD[T]: return an RDD containing elements only found in both RDDs -
subtract(other: RDD[T]): RDD[T]: return an RDD containing elements only found in both RDDs -
cartesian[U](other: RDD[U]): RDD[(T, U)]: Cartesian product with other RDD
Here are a few common actions:
-
collect(): Array[T]: return all elements from RDD -
count(): Long: return the number of elements in the RDD -
take(num: Int): Array[T]: return the firstnumelements of theRDD -
reduce(op: (A, A) => A): A: combine the elements in the RDD together usingopand return result -
foreach(f: T => Unit): Unit: applyfto each element in the RDD -
takeSample(withRepl: Boolean, num: Int): Array[T]: return array with a random sample of num elements of the dataset, with or without replacement -
takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]: return first n elements of the RDD using either their natural order or a custom comparator -
saveAsTextFile(path: String): Unit: write elements of the dataset as a textr file in the local filesystem or HDFS -
saveAsSequenceFile(path: String): Unit: write the elements of the dataset as a Hadoop SequenceFile in the local filesystem or HDFS
Let’s do another example. Assume that we have an RDD[String] which contains gigabytes of logs collected over the previous years. Dates come in the form YYYY-MM-DD:HH:MM:SS, errors are logged with a prefix including the word “error”. To determine the number of errors that were logged in December 2016:
1
2
3
4
val lastYearsLogs: RDD[String] = ...
val numDecErrorLogs =
lastYearsLogs.filter(lg => lg.contains("2016-12" && lg.contains("error")))
.count()
Benefits of laziness for Large-Scale Data
Consider the following examples:
1
2
val lastYearsLogs: RDD[String] = ...
val firstLogsWithErrors = lastYearsLogs.filter(_.contains("ERROR")).take(10)
Spark can leverage the fact that filter is deferred until take by analyzing and optimizing the chain of operations before executing it to reduce the number of iterations. Spark will not compute intermediate RDDs. Instead, in this case, as soon as 10 elements of the filtered RDD have been computed, it is done.
Caching and Persistence
Let’s look at an example. A logistic regression follows the following formula:
Let’s try to implement it in a straightforward way:
1
2
3
4
5
6
7
8
val points = sc.textFile(...).map(parsePoint)
var w = Vector.zeros(d) // initialize weights to 0
for (i <- 1 to numIterations) {
val gradient = points.map { p =>
(1 / (1 + exp(-p.y * w.dot(p.x))) - 1) * p.y * p.y
}.reduce(_ + _)
w -= alpha * gradient
}
We use a reduce, so we call numIterations actions. Notice how the reduce is done on points: this is problematic, because Spark recomputes an RDD every time we call an action on it. In our example above, we’re calling parsePoint waaaay too many times! To tell Spark to cache an RDD in memory (say if we need to use it multiple times), we can call .persist() or .cache() on them.
1
2
3
4
5
6
7
8
val points = sc.textFile(...).map(parsePoint).persist() // huge perf improvement
var w = Vector.zeros(d) // initialize weights to 0
for (i <- 1 to numIterations) {
val gradient = points.map { p =>
(1 / (1 + exp(-p.y * w.dot(p.x))) - 1) * p.y * p.y
}.reduce(_ + _)
w -= alpha * gradient
}
There are many ways to configure how your data is persisted:
- In memory as regular Java objects
- On disk as regular Java objects
- In memory as serialized Java objects (more compact)
- On disk as serialized Java objects
- Both in memory and on disk (spill over to disk to avoid re-computation)
.cache() is a shorthand for the default, which is in memory only, as regular Java objects. .persist() can be customized.
Reductions
Remember that fold and aggregate are parallelizable, but foldLeft isn’t. Therefore, Spark implements fold, reduce, aggregate on RDDs, but not foldLeft or foldRight. Why can’t it just implement it sequentially? Well, it takes a lot of synchronization to do things serially across a cluster, which is difficult, and it doesn’t make a lot of sense on a cluster.
So since those aren’t an option, we’ll have to use aggregate is we need to change the return type of our reduction operation.
Distributed Key-Value Pairs (Pair RDDs)
In single-node Scala, we had maps. In Spark, we think of those as key-value pairs, or Pair RDDs. In practice, this is a data structure that is used very often for big data analysis; most computations map data to a key-value pair, and reduce it to a final result.
Pair RDDs have additional, specialized methods for working with data associated with keys.
1
2
3
4
5
6
RDD[(K, V)] // Treated specially by Spark!!
// Methods include:
def groupByKey(): RDD[(K, Iterable[V])]
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
Creating a Pair RDD
Pair RDDs are most often created from already-existing non-pair RDDs, for example by using the map operation:
1
2
val rdd: RDD[WikipediaPage] = ...
val pairRdd = rdd.map(page => (page.title, page.text))
groupByKey
In regular Scala, we had groupBy:
1
2
3
// Partitions this traversabel collection into a map of traversable
// collections according to some discriminator function
def groupBy[K](f: A => K): Map[K, Traversable[A]]
In English: it breaks up a collection into two or more collections according to a function that we pass to it.
- Key: The result of the function
- Value: The collection of elements that return that key when the function is applied to it
Spark’s groupByKey can be thought of as a groupBy on Pair RDDs that is specialized in grouping all values that have the same key. As a result, it takes no argument, no discriminator function.
1
def groupByKey(): RDD[(K, Iterable[V])]
In English:
- Key: Key
- Value: The collection of values with the given key
reduceByKey
reduceByKey can be thought of as a combination of groupByKey and reduce on all the values per key. It’s more efficient though, than using each separately.
1
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
The function only cares about the values: we assume that the elements are already grouped by key, and now we apply this reduction function.
mapValues
1
def mapValues[U](f: V => U): RDD[(K, U)]
Can be thought of as a short-hand for:
1
rdd.map { case (x, y): (x, f(y)) }
That is, it simply applies a function to the values in a Pair RDD.
countByKey
1
def countByKey(): Map[K, Long]
Simply counts the number of elements per key in a Pair RDD, returning a normal Scala Map (this is an action) mapping keys to counts.
keys
1
def keys: RDD[K]
This returns a RDD with the keys of each tuple (this is a transformation).
Example
1
2
3
4
5
6
7
8
val intermediate =
eventsRdd.mapValues(b => (b, 1)) // (org, (budget, 1))
.reduceByKey((a, b) => (a._1 + b._1, a._2 + b._2)) // (org, (totalBudget, total#events))
val avgBudgets = intermediate.mapValues {
case (budget, numberEvents) => budget / numberOfEvents
}
avgBudgets.collect().foreach(println) // (org, avgBudget)
Joins
Joins are unique to Pair RDDs. They’re used to combine multiple datasets. There are 2 kinds of joins:
- Inner joins (
join) - Outer joins (
leftOuterJoin,rightOuterJoin)
The key difference between the two is what happens to the keys when both RDDs don’t contain the same key.
1
2
3
4
5
6
7
8
// Returns a new RDD containing combined pairs whose
// keys are present in BOTH RDDs
def join[W](other: RDD[K, W]): RDD[(K, (V, W))]
// Outer joins return a new RDD containing combined pairs
// whose key don't have to be present in both input RDDs
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
def rightOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (Option[V], W))]
The choice between leftOuterJoin and rightOuterJoin should be made by deciding which data is optional.
Shuffles
1
2
3
4
val pairs = sc.parallelize(List((1, "one"), (2, "two"), (3, "three")))
pairs.groupByKey()
// res2: org.apache.spark.rdd.RDD[(Int, Iterable[String])]
// = ShuffledRDD[16] at groupByKey at <console>:37
We typically have to move data from one node to another to be grouped by key; doing this is called “shuffling”. They are an enormous hit to performance because Spark must send data from one node to another over the network (latency costs!).
To minimize these latency costs, we can reduce the amount of data being sent over the network. This is why reduceByKey is more efficient than groupByKey: it does a groupByKey and reduce locally, then sends the reduced information around for a second round of reduceByKey. This means a non-trivial reduction of data shuffling (in a simple example, we get a 3x speedup).
Partitioning
How does Spark know which key to put on which machine? By default, it uses hash partitioning to determine which key-value pair should be sent to which machine.
The data within an RDD is split into several partitions.
- Partitions never span multiple machines; tuples in the same partition are guaranteed to be on the same machine
- Each machine in the cluster contains one or more partitions
- The number of partitions to use is configurable. By default, it’s the total number of cores on all executor nodes
There are two kinds of partitioning in Spark:
- Hash partitioning: attempts to spread the data evenly across partitions based on the keys (
partition = k.hashCode() % numPartitions) - Range partitioning: when an ordering is defined on the keys, range partitioning may be more efficient. Keys are partitioned according to their ordering and a set of sorted ranges of keys.
Customizing a partitioning is only possible on Pair RDDs. There are two ways to set partitioning for our data:
- Call
partitionByon an RDD, providing an explicitPartitioner - Using transformations that return RDDs with specific
Partitioners- From parent RDD: the result of a transformation on a partitioned Pair RDD typically is configured to use the hash partitioner that was used to construct it
- Automatically-set partitioners: some operations result in an RDD with a known partitioner, for when it makes sense (
sortByKeyuses aRangePartitioner,groupByKeyuses aHashPartitioner)
Let’s look at partitionBy:
1
2
3
val pairs: RDD[(Int, Int)] = ...
val tunedPartitioner = new RangePartitioner(8, pairs) // Spark will figure out the best partitioning
val partitioned = pairs.partitionBy(tunedPartitioner).persist() // persist so we don't have to shuffle data multiple times
The result of partitionBy should always be persisted. Otherwise, the partitioning is repeatedly applied (involving shuffles) each time.
For partition resulting from transformations, the following operations on Pair RDDs hold on to (and propagate) a partitioner:
-
cogroup,groupWith,groupByKey -
join,leftOuterJoin,rightOuterJoin -
reduceByKey,foldByKey,combineByKey partitionBysort- If the parent has a partitioner:
mapValues,flapMapValues,filter
All other operations will produce a result without a partitioner. Interestingly, map and flatMap aren’t on the list, since they can change the key; using them makes us lose our partitioning.
Optimizing with Partitioners
Using range partitioners we can optimize use of reduceByKey so that it doesn’t involve any shuffling over the network:
1
2
3
4
5
6
7
val pairs: RDD[(Int, Int)] = ...
val tunedPartitioner = new RangePartitioner(8, pairs)
val partitioned = pairs.partitionBy(tunedPartitioner).persist()
val purchasesPerCustomer = partitioned.mapValues((1, _))
val purchasesPerMonth = purchasesPerCustomer.reduceByKey{
case ((a, b), (c, d)) => (a + c, b + d)
}.collect()
This is almost 9x faster than our initial examples.
As a rule of thumb, a shuffle can occur when the resulting RDD depends on other elements from the same RDD or another RDD. Here’s a list of operations that might cause a shuffle:
-
cogroup,groupWith,groupByKey -
join,leftOuterJoin,rightOuterJoin -
reduceByKey,combineByKey -
distinct,intersection -
repartition,coalesce
There are ways to use these operations and still avoid much or all network shuffling. For instance, by running reduceByKey on a pre-partitioned RDD, or by running join on two RDDs that are pre-partitioned with the same partitioner and cached on the same machine, we avoid almost all network shuffling.
Wide vs Narrow Dependencies
Computations on RDDs are represented as a lineage graph, a directed acyclic graph (DAG) representing the computations done on the RDD. Spark analyses the lineage graph to do optimizations.
Remember the rule of thumb above. Dependency information can tell us when a shuffle may occur. There are two kinds of dependencies:
-
Narrow Dependencies: each partition of the parent RDD is used by at most one partition of the child RDD
-
join(with co-partitioned inputs) -
map,mapValues,flatMap,filter,union,mapPartitions,mapPartitionsWithIndex
-
-
Wide Dependencies: each partition of the parent RDD may be depended on by multiple child partitions
-
join,leftOuterJoin,rightOuterJoin(with inputs not co-partitioned) -
cogroup,groupWithgroupByKey,groupBy,reduceByKey,combineByKey,distinct,intersection,repartition,coalesce…
-
The former is fast! No shuffling is necessary, and optimizations like pipelining are possible. The latter is slow — it requires some or all of the data to be shuffled over the network.
THere is a dependencies method on RDDs. It returns a sequence of Dependency objects, which are the dependencies used by Spark’s scheduler to know how this RDD depends on other RDDs.
The sorts of dependency objects it may return include:
-
Narrow dependency objects:
OneToOneDependency,PruneDependency,RangeDependency -
Wide dependency objects:
ShuffleDependency
Another helpful method is toDebugString, which prints out a visualization of the RDD’s lineage, and other relevant scheduling information.
Lineage graphs are the key to fault tolerance in Spark: we can recover from failures by recomputing lost partitions from the lineage graphs (we can just recompute the partition, not the whole data set). This allows fault tolerance without writing to disk, which is why Spark is so fast.
Recomputing missing partitions is fast for narrow dependencies, but slow for wide dependencies.
Structured and Unstructured Data
In Spark, there are often multiple ways of achieving the same result, often with very different running times. For instance, filtering before joining is faster than joining before filtering, which itself is faster than computing a Cartesian product and then filtering.
Sometimes, the way we pick isn’t the fastest one; it would be great if Spark could optimize our commands to the fastest version! That’s what Spark SQL does: given a bit of extra structural information, Spark can do many optimizations for us!
All data isn’t created equal, structurally. It falls on a spectrum from unstructured (log files, images), to semi-structured (JSON, XML), to structured (database tables). With RDD, we’ve been working with unstructed or semi-structured data, where we don’t know anything about the schema of the data we’re working with (we just have generic typing, without knowing what’s inside of the objects). The same can be said about computation; lambda operations are opaque to Spark (they’re not predefined like in SQL).
We’ve got to give up some of the freedom, flexibility and generality of the functional collections API in order to give Spark more opportunities to optimize.
Spark SQL
Spark SQL is a Spark library with 3 main goals:
- Support relational processing within Spark and on external data sources, so that we can mix SQL and functional APIs.
- High performance
- Support new data sources such as semi-structured data and external databases (it’s usually complicated to connect big data processing pipelines like Spark or Hadoop to an SQL database, but Spark SQL makes it easy).
The three main APIs are:
- SQL literal syntax
DataFramesDatasets
In the back-end, it adds:
- Catalyst, a query optimizer
- Tungsten, off-heap serializer (encodes Scala objects efficiently off the heap, away from the garbage collector)
Getting started
DataFrame is Spark SQL’s core abstraction. Conceptually, it’s equivalent to a table in a relational database. Conceptually, it’s an RDD full of records with a known schema. Unlike RDDs, DataFrames are untyped (no type paramater), but require schema information. One final terminological point: transformations on DataFrames are called untyped transformations.
To get started using Spark SQL, we’ll start with SparkSession (the equivalent of SparkContext):
1
2
3
4
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().appName("My App")
// .config("spark.some.config.option", "some-value")
.getOrCreate()
Data frames can be created in two ways. Either from an existing RDD:
1
2
3
4
5
6
val tupleRDD: RDD[(Int, String, String, String)] = ...
val tupleDF = tupleRDD.toDF("id", "name", "city", "country") // column names
case class Person(id: Int, name: String, city: String)
val peopleRDD: RDD[Person] = ...
val peopleDF = peopleRDD.toDF // column names are automatically infered from Person
Or, in another way, by defining a schema explicitly:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
case class Person(name: String, age: Int)
val peopleRDD: RDD[Person] = ...
// Step 1: create an RDD of rows from the original RDD
val rowRDD = peopleRDD.map(_.split(","))
.map(attributes => Row(attributes(0), attributes(1).trim))
// Step 2: create the schema represented by a StructType matching the structure of the rows
val schemaString = "name age"
val fields = schemaString.split(" ")
.map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema = StructType(fields)
// Step 3: Apply the schema to the RDD of rows via createDataFrame
val peopleDF = spark.createDataFrame(rowRDD, schema)
We can also read from a source file (it supports JSON, CSV, Parquet, JDBC… see the documentation):
1
val df = spark.read.json("examples/src/main/resourceds/people.json")
Once we have a DataFrame, we can freely write SQL syntax. We just have to register it as a temporary SQL view first:
1
2
3
4
// give it a name for the SQL FROM statement
peopleDF.createOrReplaceTempView("people")
val adultsDF = spark.sql("SELECT * FROM people WHERE age > 17")
See this cheat sheet for supported SQL statements.
DataFrames
DataFrames are a relational API over Spark’s RDD, which can be aggressively optimized. Another thing to remember is that they’re untyped; the elements with DataFrames are Rows, which aren’t parameterized by a type, so the compiler cannot type check Spark SQL.
SQL does have types though; in order to access any of them, you must first import Spark SQL types:
1
import org.apache.spark.sql.types._
The DataFrames API contains operations that look similar to SQL, including, but not limited to, select, where, limit, orderBy, groupBy, join, …
To see what a DataFrame looks like, we can use .show(), which pretty prints the data’s first 20 elements in tabular form. .printSchema() prints the schema in tree format.
There are a few different ways to specify columns. The syntax is flexible, as it goes through an SQL parser, but the first two are often a little less error-prone:
1
2
3
4
5
6
7
8
9
// 1. Using $ notation
// requires import spark.implicits._
df.filter($"age" > 18)
// 2. Referring to the DataFrame
df.filter(df("age") > 18)
// 3. Using SQL query string
df.filter("age > 18")
Note: where and filter are exactly equivalent. Use whichever looks/sounds best.
Like on RDDs, transformations on DataFrames are operations which return a DataFrame as a result, and are lazily evaluated. As an example, assume we have a dataset of homes currently for sale in an entire US state. We want the most expensive and the least expensive homes for sale per zip code.
1
2
3
4
5
6
7
import org.apache.spark.sql.functions._
case class Listing(street: String, zip: Int, price: Int)
val listingsDF = ... // DataFrame of Listings
val mostExpensiveDF = listingsDF.groupBy($"zip").max("price")
val leastExpensiveDF = listingsDF.groupBy($"zip").min("price")
Another example: we want to find the person with the most posts in each subforum of a forum:
1
2
3
4
5
6
7
8
import org.apache.spark.sql.functions._
case class Post(authorID: Int, subforum: String, likes: Int, date: String)
val postsDF = ... // DataFrame of Posts
val rankedDF = postsDF.groupBy($"authorID", $"subforum")
.agg(count($"authorId")) // new DF with cols for authorId, subforum, count(authorId)
.orderBy($"subforum", $"count(authorId)".desc) // desc for "descending order"
Some of the transformations return specific kinds of DataFrames on which we can only execute certain actions. Here’s a list of methods that can be called on a RelationalGroupedDataset (after a groupBy), and here’s a list of methods that can be called within agg.
Cleaning Data with DataFrames
Sometimes, data sets have null or NaN values. In these cases it’s often desirable to:
- Drop rows with unwanted values:
-
drop()drops rows that containnullorNaNvalues in any column and returns a new DataFrame -
drop("all")drops rows that containnullorNaNvalues in all columns and returns a new DataFrame -
drop(Array("id", "name"))drops rows that containnullorNaNvalues in the specified columns and returns a new DataFrame
-
- Replace certains values with a constant:
-
fill(0)replaces all occurrences ofnullorNaNin numeric columns with the specified value and returns a new DataFrame -
fill(Map("minBalance" -> 0))replaces all occurrences ofnullorNaNin specified column with the specified value and returns a new DataFrame -
replace(Array("id"), Map(1234 -> 8923))replaces the specified value (1234) in the specified column (id) with the specified replacement value (8923) and returns a new DataFrame
-
Common actions on DataFrames
-
collect(): Array[Row]: returns an array containing all rows in the DataFrame -
count(): Long: returns the number of rows in the DataFrame -
first(): Roworhead(): Row: returns the first row in the DataFrame -
show(): Unit: displays the top 20 rows in tabular form -
take(n: Int): Array[Row]: returns the firstnrows
Joins on DataFrames
Joins on DataFrames are similar to those on Pair RDDs, but since DataFrames aren’t key/value pairs, we have to specify which columns to join on.
There are several types of joins available: inner, outer, left_outer, right_outer, leftsemi.
1
2
3
4
5
6
// Both df1 and df2 have a column called id
// Inner join is performed like this:
df1.join(df2, $"df1.id" === $"df2.id")
// Other types of joins are done like this:
df1.join(df2, $"df1.id" === $"df2.id", "right_outer")
Optimizations on DataFrames
The great advantage of working with DataFrames is that queries are automatically optimized. Revisiting our award example, we don’t have to put too much thought into performance, and we can just do what seems most natural and enjoy optimized performance:
1
2
3
4
demographicsDF.join(financesDF, demographicsDF("ID") === financesDF("ID"), "inner")
.filter($"HasDebt" && $"HasFinancialDependents")
.filter($"CountryLive" === "Switzerland")
.count
In practice, compared to the previous Spark RDD version, the DataFrame version is even faster! How is this possible?
Recall that Spark comes with Catalyst, which is Spark SQL’s query optimizer, which compiles Spark SQL programs down to an RDD. It can:
- Reorder operations: The laziness and structure inherent to Catalyst gives it the ability to analyze and rearrange the DAG of the computation before it’s executed
- Reduce the amount of data we must read: Catalyst can skip reading in, serializing and sending around parts of the data set that aren’t needed for our computation
- Pruning unneeded partitioning: it analyzes DataFrames and filter operations to figure out and skip partitions that are unneeded in our computation
- And more!
Tungsten in Spark SQL’s off-heap data encorder. It takes schema information and tightly packs serialized data into memory. This means more data can fit in memory, and faster serialization/deserialization can occur. Data is stored off-heap, where it’s free from garbage collection overhead.
Limitations
- Untyped: errors aren’t caught at compile time, they’re caught at execution time
-
Limited data types: data that can’t be expressed by
case classorProductor standard Spark SQL data types is hard to encode with Tungsten; it doesn’t always play well with old codebases. - Requires semi-structured or structured data: some data doesn’t fit nicely in DataFrames (images, logs, etc).
Datasets
Datasets provide an alternative framework to DataFrames. As an example, let’s say we we want the average price of home listings:
1
2
3
4
5
6
7
case class Listing(street: String, zip: Int, price: Int)
val listingsDF = ... // DataFrame of Listings
import org.apache.spark.sql.functions._
val averagePricesDF = listingsDF.groupBy($"zip").avg("price")
val averagePrices = averagePricesDF.collect()
// averagePrices: Array[org.apache.spark.sql.Row]
We wanted an Array[Double], what is this Row thing? We have to cast things because Rows don’t have type information associated with them.
1
2
3
val averagePricesAgain = averagePrices map {
row => (row(0).asInstanceOf[String], row(1).asInstanceOf[Int])
}
This gives us an exception. Well, what about looking at the Row API docs? That reveals that we can do this:
1
2
3
4
averagePrices.head.schema.printTreeString()
// root
// |-- zip: integer (nullable = true)
// |-- avg(price): double (nullable = true)
Ah, so we had a mistake in our types! But rather than doing it that way, wouldn’t it be nice to have both Spark SQL and type safety? Enter Datasets: they combine type safety with Spark SQL. DataFrames are in fact Datasets themselves:
1
type DataFrame = Dataset[Row]
The Dataset API unifies the DataFrame and RDD APIs. We can mix and match relational and functional operators! Like DataFrames, they require structured/semi-structured data. Schemas and Encoder are a core part of Datasets.
Recall the Column type from DataFrames. On Datasets, typed operations tend to act on TypedColumn instead. To create a TypedColumn, all you have to do is call as[...] on your untyped Column.
Creating Datasets
First, see Getting Started for general setup. Once that is done, there are a number of ways of creating a Dataset:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 1. From a DataFrame:
import spark.implicits._
val myDS = myDF.toDS
// 2. Reading from JSON, using read on the SparkSession object and
// then converting to a Dataset:
val myDS = spark.read.json("people.json").as[Person]
// 3. From an RDD:
import spark.implicits._
val myDS = myRDD.toDS
// 4. From common Scala types:
import spark.implicits._
val myDS = List("a", "b", "c").toDS
Transformations on Datasets
The Dataset API includes:
-
Typed transformations typed variants of many
DataFrametransformations and additional transformations such as RDD-like higher-order functionmap,flatMap, etc.map[U](f: T => U): Dataset[U]flatMap[U](f: T => TraversableOnce[U]): Dataset[U]filter(pred: T => Boolean): Dataset[T]distinct(): Dataset[T]-
groupByKey[K](f: T => K): KeyValueGroupedDataset[K, T]: Like onDataFrames,Datasets have a special set of aggregation operations meant to be used after a call togroupByKey, hence the different return type. Operations include:-
reduceGroups(f: (V, V) => V): Dataset[(K, V)]: reduce on the elements of each group. The function must be commutative and associative. -
agg[U](col: TypedColumn[V, U]): Dataset[(K, U)]: aggregates using the given Spark SQL function, for instancesomeDS.agg(avg($"column").as[Double]). We use the.asmethod to make it aTypedColumn, and then everything type checks. -
mapGroups[U](f: (K, Iterator[V]) => U): DataSet[U]: maps on the collection of values for each group. A big disclaimer on it though: it does not suport partial aggregation, and as a result requires shuffling all the data in the Dataset. If an application intends to perform an aggregation over each key, it is best to use thereducefunction or an Aggregator. flatMapGroups[U](f: (K, Iterator[V]) => TraversableOnce[U]): Dataset[U]
-
-
coalesce(numPartitions: Int): Dataset[T]: apply a function to each element in the Dataset and return aDatasetof the contents of the iterators returned repartition(numPartitions: Int): Dataset[T]
-
Untyped transformations the transformations we learned on
DataFrames
Aggregators
A class that helps you generically aggregate data. Kind of like the aggregate method on RDDs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// Location:
import org.apache.spark.sql.expressions.Aggregator
// Definition:
class Aggregator[-IN, BUF, OUT]
// Implementation idea:
val myAgg = new Aggregator[IN, BUF, OUT] {
def zero: BUF = ... // Initial value
def reduce(b: BUF, a: IN): BUF = ... // Add an element to the running total
def merge(b1: BUF, b2: BUF): BUF = ... // Merge intermediate values
def finish(b: BUF): OUT = ... // Return final result
override def bufferEncoder: Encoder[BUF] = ... // disregard for now
override def outputEncoder: Encoder[OUT] = ... // disregard for now
}.toColumn
-
INis the input type to the aggreagtor. When using an aggregator aftergroupByKey, this is the type that represents the value in the key/value pair -
BUFis the intermediate type during aggregation -
OUTis the type of the output of the aggregation
To use it, we have to define the types and methods:
1
2
3
4
5
6
7
8
9
10
11
12
val keyValues = List((3, "Me"), (1, "Thi"), (2, "Se"), (3, "ssa"), ...)
val keyValuesDS = keyValues.toDS
val strConcat = new Aggregator[(Int, String), String, String] {
def zero: String = ""
def reduce(b: String, a: (Int, String)): String = b + a._2
def merge(b1: String, b2: String): String = b1 + b2
def finish(r: String): String = r
}.toColumn
keyValuesDS.groupByKey(pair => pair._1)
.agg(strConcat.as[String])
But this gives us an error telling us to define bufferEncoder and outputEncoder. To understand this, we first need to understand what an Encoder is. They are what convert your data between JVM objects and Spark SQL’s specialized internal tabular representation. They’re required by all Datasets! There are two ways to introduce encoders:
-
Automatically (generally the case) via implicits from a
SparkSession(import spark.implicits._) -
Explicitly via
org.apache.spark.sql.Encoderwhich contains a large selection of methods for creatingEncodersfrom Scala primitive types andProducts. Some example ofEncodercreation methods inEncoders:-
INT,LONG,STRINGfor nullable primitives -
scalaInt,scalaLong,scalaBytefor Scala primitives -
product,tuplefor Scala’sProductandtupletypes
-
Example of explicitily creating Encoders:
1
2
3
Encoders.scalaInt // Encoder[Int]
Encoders.STRING // Encoder[String]
Encoder.product[Person] // Encoder[Person], where "Person extends Product" is a case class
So we actually also need to define the encoders for our example. This is pretty straightforward once we’ve replaced the IN, BUF and OUT types:
1
2
3
4
5
6
7
8
9
10
11
val strConcat = new Aggregator[(Int, String), String, String] {
def zero: String = ""
def reduce(b: String, a: (Int, String)): String = b + a._2
def merge(b1: String, b2: String): String = b1 + b2
def finish(r: String): String = r
override def bufferEncoder: Encoder[String] = Encoders.STRING
override def outputEncoder: Encoder[String] = Encoders.STRING
}.toColumn
keyValuesDS.groupByKey(pair => pair._1)
.agg(strConcat.as[String]).show
Dataset Actions
All the actions are exactly the same as we’ve previously seen on RDDs and on DataFrames.
collect(): Array[T]count(): Long-
first(): Torhead(): T foreach(f: T => Unit): Unitreduce(f: (T, T) => T): Tshow(): Unittake(n: Int): Array[T]
Limitations of Datasets
Catalyst can’t optimize all operations. Lambda functions can’t be optimized as they are opaque to the optimizer; equivalent relational calls can however be optimized.
- When using Datasets with higher-order functions like
map, you miss out on many Catalyst optimizations - When using Datasets with relational operations like
select, you get all of Catalysts’s optimizations - Thoough not all operations can be optimized by Catalyst, Tungsten is still running under the hood to serialize data in a highly optimized way
If the data can’t be expressed by case classes or Products and standard Spark SQL data types, it may be difficult to ensure that a Tungsten encoder exists (this is often a problem for legacy code using regular Scala class).
If your unstructured data cannot be reformulated to adhere to some kind of schema it would be better to use RDDs.
Datasets vs DataFrames vs RDDs
To finish this course on Spark, a bit of discussion on when to use the different technologies:
Use Datasets when:
- you have structured or semi-structured data (JSON, XML, CSV, …)
- you want type safety
- you need to work with functional APIs
- you need good performance, but it doesn’t have to be the best
Use DataFrames when:
- you have structured or semi-structured data
- you want the best possible performance, automatically optimized for you
Use RDDs when:
- you have unstructured data
- you need to fine-tune and manage low-level details of RDD computations
- you have complex data types that cannot be serialized with
Encoders